
SEO Spiders: Por Que Eles São Importantes para o Seu Site
Spiders são bots criados para spamming, que podem causar muitos problemas para o seu negócio. Saiba mais sobre eles no artigo.
4
SEO
DigitalMarketing
+3
Descubra por que os rastreadores da web são chamados de spiders, como funcionam e seu papel fundamental na indexação dos mecanismos de busca. Conheça os mecanismos técnicos por trás do web crawling em 2025.
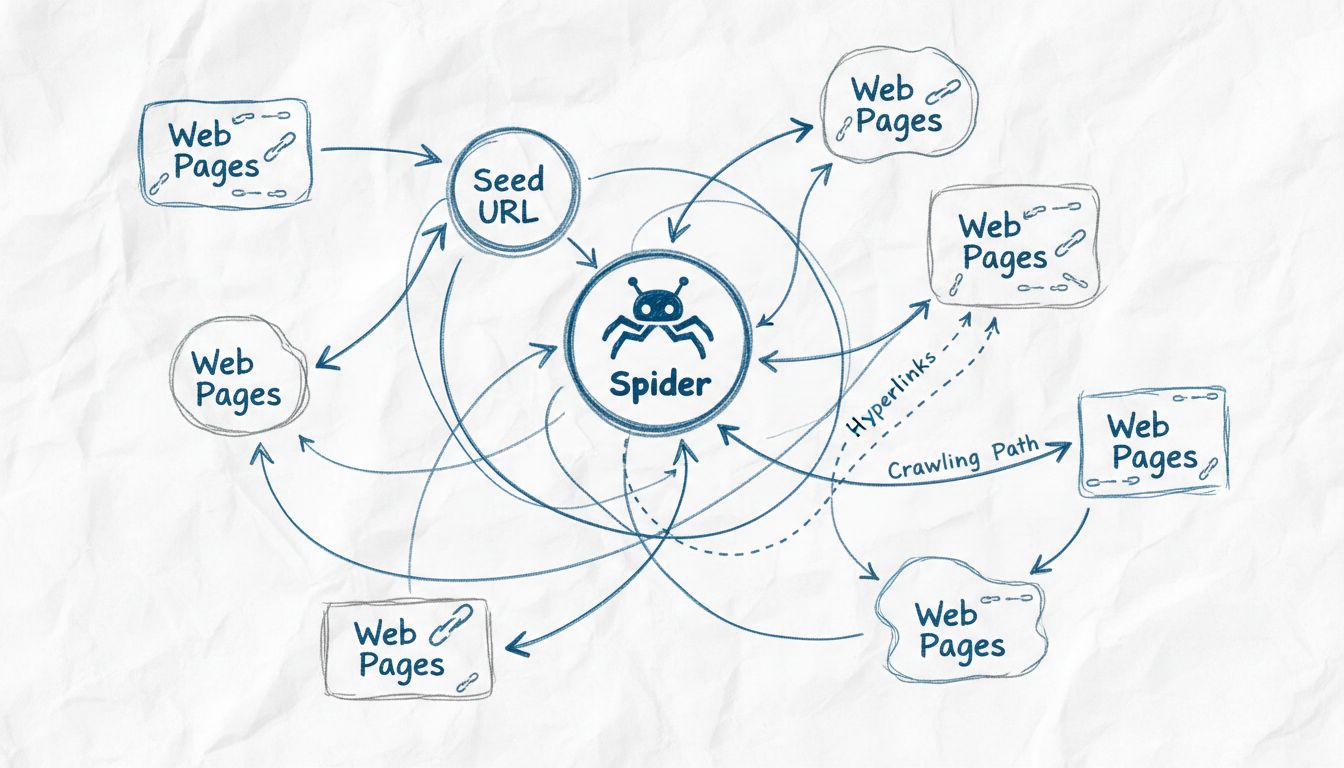
Os rastreadores da web são chamados de spiders porque percorrem sistematicamente a web seguindo links de uma página para outra, assim como uma aranha navega em sua teia. O termo 'spider' é uma metáfora apropriada para esses bots automatizados que transitam pela rede interconectada de sites para descobrir, indexar e organizar conteúdos para os mecanismos de busca.
O termo “spider” para rastreadores da web origina-se de uma comparação metafórica inteligente entre como esses bots automatizados navegam na internet e como as aranhas reais se movimentam em suas teias. Assim como uma aranha tece uma teia intrincada para capturar e organizar informações sobre seu ambiente, os rastreadores da web percorrem a rede interconectada de hiperlinks da World Wide Web para descobrir, analisar e organizar conteúdos digitais. A metáfora é especialmente apropriada porque ambas as entidades operam de forma sistemática por meio de redes complexas, seguindo caminhos para alcançar novos destinos e coletar informações. Essa convenção de nomenclatura tornou-se tão enraizada na tecnologia que os termos “spider”, “crawler” e “bot” agora são usados de forma intercambiável ao discutir tecnologia de indexação web. A semelhança visual e conceitual entre a teia de uma aranha e a estrutura da internet torna essa terminologia intuitiva e fácil de memorizar tanto para profissionais técnicos quanto para usuários em geral.
Os spiders da web operam através de um processo sofisticado e sistemático que começa com um ponto de entrada chamado “seed URL”. A partir desse local inicial, o spider analisa o código HTML da página, extraindo todos os hiperlinks presentes nela. O spider então segue esses links para novas páginas, repetindo continuamente o processo para expandir seu alcance pela web. Essa abordagem metódica permite aos spiders descobrir milhões de páginas interconectadas sem a necessidade de orientação manual ou intervenção humana. O spider mantém o que é conhecido como “crawl frontier”, que é basicamente uma fila de URLs descobertas, mas ainda não visitadas. Com base em políticas e algoritmos de rastreamento específicos, o spider prioriza quais URLs visitar em seguida, considerando fatores como importância da página, frequência de atualização e relevância para os objetivos de indexação do mecanismo de busca.
Configure o rastreamento avançado em minutos. Não é necessário cartão de crédito.
Os spiders modernos são construídos sobre uma arquitetura técnica sofisticada, que permite processar grandes volumes de dados com eficiência. Os componentes principais de um rastreador incluem o sistema de gerenciamento da fila de URLs, que organiza e prioriza URLs para rastreamento; o mecanismo de busca, que faz download do conteúdo das páginas em alta velocidade; o motor de parsing, que extrai links e metadados do HTML; e o sistema de indexação, que armazena as informações processadas para busca posterior. Os spiders também devem implementar políticas de polidez para evitar sobrecarregar servidores com requisições excessivas, políticas de revisita para determinar com que frequência páginas devem ser re-rastreadas em busca de atualizações e políticas de seleção para decidir quais links são mais valiosos para seguir. Spiders contemporâneos evoluíram para lidar com conteúdo em JavaScript e AJAX, embora ainda priorizem HTML padrão para uma descoberta confiável de conteúdo. A natureza distribuída do rastreamento moderno faz com que spiders em larga escala operem em múltiplos servidores simultaneamente, permitindo rastrear diferentes sites em paralelo e aumentar significativamente sua eficiência e cobertura.
Embora os termos “spider” e “crawler” sejam frequentemente usados como sinônimos, é importante entender que representam a mesma tecnologia com diferentes convenções de nomenclatura. No entanto, spiders da web diferem significativamente de scrapers, que às vezes são confundidos com crawlers. A principal distinção está no propósito e no escopo: rastreadores da web focam na coleta geral de informações sobre sites e sua estrutura, seguindo links amplamente pela web para criar índices abrangentes. Spiders, quando usados especificamente por buscadores, concentram-se na indexação de conteúdo textual para torná-lo pesquisável e descobrível. Já os scrapers são ferramentas de precisão projetadas para extrair elementos específicos de dados dos sites, como preços de produtos, informações de contato ou avaliações. Scrapers normalmente miram sites ou tipos de dados específicos, em vez de rastrear amplamente a web. Além disso, crawlers e spiders geralmente respeitam arquivos robots.txt e os termos de serviço do site, enquanto scrapers podem operar sem essas restrições. Entender essas distinções é fundamental para proprietários e desenvolvedores de sites que precisam gerenciar como seu conteúdo é acessado e indexado por sistemas automatizados.
Seja o primeiro a saber sobre novos recursos e atualizações do produto.
Os spiders da web são absolutamente fundamentais para o funcionamento dos mecanismos de busca e para o valor que eles oferecem aos usuários no mundo todo. Sem spiders rastreando e indexando continuamente o conteúdo da web, os buscadores não teriam como saber quais sites existem, que conteúdo eles possuem ou quão relevante esse conteúdo pode ser para as consultas dos usuários. Quando um spider rastreia uma página, ele avalia diversos fatores, incluindo estrutura da página, relevância do conteúdo, uso de palavras-chave e sinais de experiência do usuário. Essas informações são então armazenadas em enormes índices que os buscadores usam para associar as consultas dos usuários aos resultados mais relevantes. A qualidade e a frequência do rastreamento dos spiders impactam diretamente a rapidez com que novos conteúdos aparecem nos resultados de busca e a precisão com que os mecanismos podem ranquear as páginas. Buscadores como Google, Bing, Baidu e Yahoo mantêm seus próprios bots proprietários—Googlebot, Bingbot, Baiduspider e Slurp, respectivamente—cada um com algoritmos e estratégias de rastreamento otimizados para os objetivos e público do seu buscador.
| Spider Bot | Mecanismo de Busca | Função Principal | Estratégia de Rastreamento | Principais Características |
|---|---|---|---|---|
| Googlebot | Indexar páginas para o Google Search | Rastreamento distribuído com variantes mobile e desktop | Lida com JavaScript, prioriza indexação mobile-first, respeita crawl budget | |
| Bingbot | Microsoft Bing | Indexar páginas para o Bing Search | Rastreamento paralelo em múltiplos servidores | Uso eficiente de banda, respeita robots.txt, suporta múltiplos tipos de conteúdo |
| Baiduspider | Baidu | Indexar páginas para o Baidu Search | Otimizado para conteúdo em chinês | Especializado em conteúdo asiático, lida com chinês simplificado e tradicional |
| DuckDuckBot | DuckDuckGo | Indexar páginas para busca focada em privacidade | Rastreamento respeitoso com ênfase em privacidade | Coleta mínima de dados, respeita preferências de privacidade do usuário |
| YandexBot | Yandex | Indexar páginas para o Yandex Search | Rastreamento distribuído com otimização regional | Otimizado para conteúdo russo e do leste europeu |
Proprietários de sites têm diversas ferramentas e estratégias para otimizar como os spiders rastreiam e indexam seu conteúdo. Criar um arquivo sitemap.xml abrangente fornece aos spiders um roteiro claro de todas as páginas que devem ser indexadas, melhorando a eficiência do rastreamento e garantindo que nenhuma página importante seja deixada de fora. Otimizar meta tags, incluindo títulos e descrições, ajuda os spiders a entender o conteúdo das páginas e melhora como elas aparecem nos resultados de busca. Implementar um arquivo robots.txt bem estruturado permite aos proprietários orientar os spiders para os conteúdos relevantes e afastá-los de páginas que não devem ser indexadas, como áreas administrativas ou conteúdo duplicado. Atualizar e adicionar conteúdos novos regularmente incentiva os spiders a revisitar o site com mais frequência, mantendo os índices atualizados e melhorando a visibilidade nas buscas. Os proprietários também devem garantir que a arquitetura do site seja limpa e lógica, com navegação hierárquica clara para facilitar a descoberta de todas as páginas pelos spiders. Melhorar a velocidade de carregamento das páginas é fundamental, pois os spiders têm um orçamento de rastreamento limitado—quantidade de recursos alocados pelos buscadores para rastrear um site—e páginas rápidas permitem que mais conteúdos sejam rastreados dentro desse orçamento.
Apesar de sua sofisticação, spiders da web enfrentam vários desafios técnicos que podem limitar sua eficácia. Conteúdo dinâmico gerado por JavaScript apresenta um obstáculo significativo, pois nem todos os spiders conseguem executar códigos JavaScript para renderizar as páginas como os usuários visualizam. Restrições de taxa impostas pelos sites limitam a quantidade de requisições que os spiders podem fazer em determinado período, o que pode impedir a indexação completa de sites grandes. CAPTCHAs e outras barreiras anti-bot podem bloquear o acesso dos spiders ao conteúdo, embora spiders legítimos de buscadores geralmente sejam autorizados. Conteúdo duplicado em múltiplas URLs confunde os spiders sobre qual versão deve ser indexada e ranqueada, podendo diluir a visibilidade nas buscas. Armadilhas de rastreamento—loops infinitos acidentais ou intencionais na estrutura do site—podem desperdiçar recursos dos spiders e consumir o orçamento de rastreamento sem adicionar valor à indexação. Além disso, o crescimento exponencial de conteúdos na web faz com que seja impossível para os spiders rastrear e indexar tudo, exigindo algoritmos sofisticados para priorizar o que é mais importante. Páginas protegidas por senha e conteúdos autenticados permanecem em grande parte inacessíveis aos spiders públicos, limitando a indexação de conteúdos privados ou restritos a membros.
A tecnologia dos spiders da web continua evoluindo rapidamente à medida que a internet cresce e se torna mais complexa. Spiders modernos são cada vez mais capazes de lidar com tecnologias web avançadas, incluindo aplicações de página única, progressive web apps e renderização dinâmica de conteúdo. Inteligência artificial e aprendizado de máquina estão sendo integrados aos algoritmos dos spiders para melhor compreender o contexto do conteúdo, a intenção do usuário e a qualidade das páginas. O avanço da IA generativa criou novas demandas para o web crawling, já que sistemas de IA exigem informações constantemente atualizadas, relevantes e precisas para funcionar de forma eficaz. Rastreadores empresariais tornaram-se cada vez mais sofisticados, permitindo que empresas rastreiem seus próprios sites para busca interna, gestão de conteúdo e monitoramento de desempenho. O foco na eficiência do rastreamento foi intensificado à medida que os sites crescem, com spiders agora implementando algoritmos de priorização mais inteligentes para maximizar o valor de cada requisição de rastreamento. Considerações de privacidade também estão moldando o desenvolvimento dos spiders, com ênfase crescente em respeitar a privacidade do usuário sem comprometer a descoberta e indexação de conteúdo. Olhando para o futuro, os spiders devem se tornar ainda mais inteligentes e eficientes, aproveitando tecnologias avançadas para navegar em um cenário digital cada vez mais complexo, respeitando as políticas dos sites e a privacidade dos usuários.
Assim como os spiders da web rastreiam e indexam sistematicamente toda a internet, o PostAffiliatePro rastreia e otimiza sistematicamente cada relacionamento de afiliado em sua rede. Nossa tecnologia avançada de rastreamento garante que nenhuma comissão fique sem registro e nenhuma oportunidade seja perdida.
Spiders são bots criados para spamming, que podem causar muitos problemas para o seu negócio. Saiba mais sobre eles no artigo.
Spiders de computador são bots especiais projetados para enviar spam ao seu endereço de e-mail ou página da web. Para evitar ataques aos seus sites, use a detec...
Crawlers acumulam dados e informações da internet visitando sites e lendo páginas. Descubra mais sobre eles.
Junte-se à nossa comunidade de clientes satisfeitos e forneça excelente suporte ao cliente com o Post Affiliate Pro.
See our privacy policy.