

Como Posso Criar um Hiperlink? Guia Completo de HTML
Aprenda como criar hiperlinks em HTML com a tag <a>. Domine atributos href, URLs absolutas e relativas, boas práticas de links e técnicas avançadas de vinculaçã...
11
Aprenda como funcionam os links de sites, entenda a estrutura de URLs, resolução de DNS e o processo técnico por trás da navegação web. Guia especializado para 2025.
Os links de sites funcionam utilizando URLs (Localizadores Uniformes de Recursos) que direcionam os navegadores para páginas web específicas. Quando você clica em um link ou digita uma URL, seu navegador usa o DNS para traduzir o nome de domínio em um endereço IP, conecta-se ao servidor e recupera o conteúdo solicitado.
Os links de sites são os blocos fundamentais da navegação na web, permitindo que os usuários transitem facilmente entre páginas e recursos em toda a internet. Um link de site é, essencialmente, uma URL (Localizador Uniforme de Recursos) que direciona o usuário para uma página exata em um site. Para que um link funcione corretamente, a URL deve ser digitada no navegador exatamente como aparece ou acessada por meio de um hyperlink. O processo de funcionamento dos links envolve várias camadas de tecnologia atuando em perfeita harmonia, desde a barra de endereços do seu navegador até os servidores distantes que hospedam o conteúdo desejado.
Entender como funcionam os links de sites é essencial para quem atua em desenvolvimento web, marketing digital ou marketing de afiliados. Ao clicar em um hyperlink ou inserir manualmente uma URL na barra de endereços do navegador, uma série complexa de eventos ocorre nos bastidores. Seu navegador precisa identificar o protocolo utilizado, localizar o servidor correto pelo Sistema de Nomes de Domínio (DNS), solicitar o recurso específico e, finalmente, renderizar o conteúdo para visualização. Todo esse processo costuma acontecer em poucos segundos, embora envolva múltiplos computadores e sistemas se comunicando pela internet.
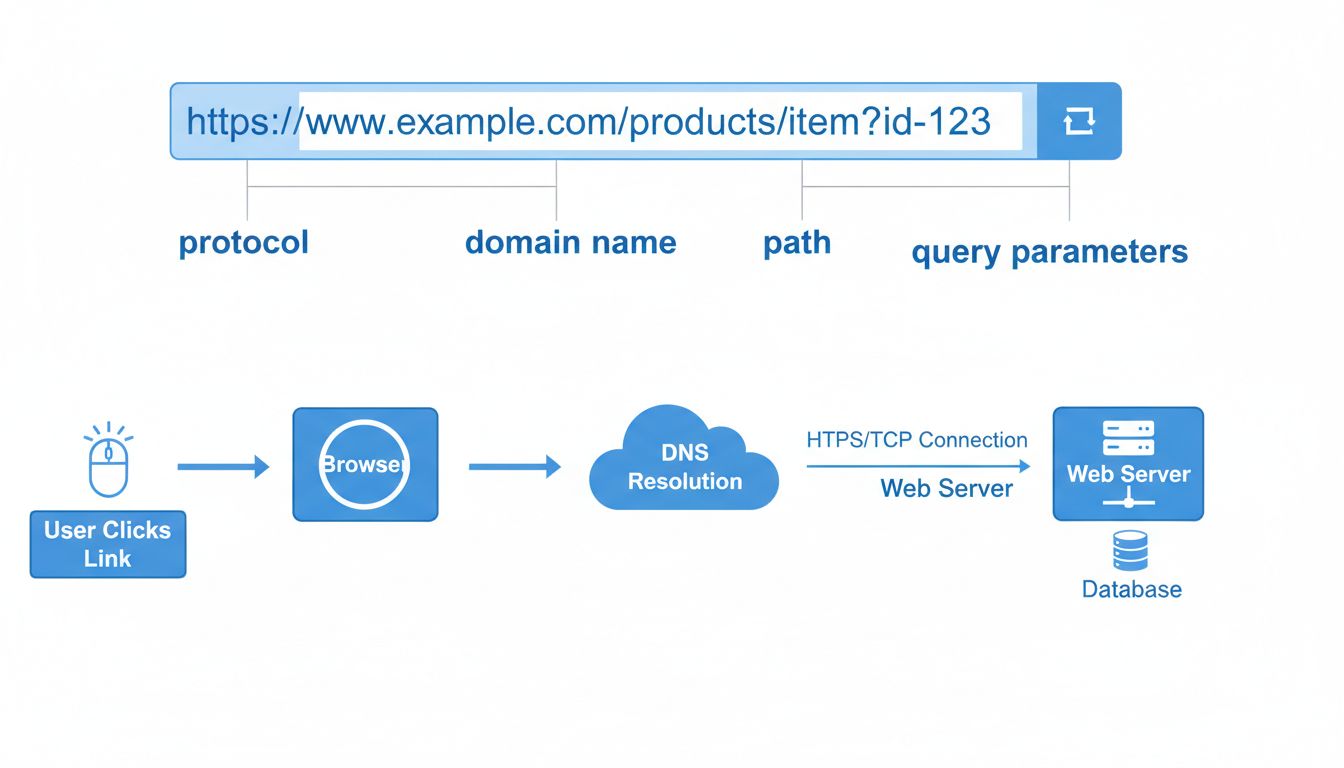
Uma URL é composta por vários componentes distintos, cada um com uma função específica para direcionar o navegador ao recurso correto. Entender esses componentes é fundamental para compreender como funcionam os links e por que a precisão é importante na digitação das URLs. A estrutura básica de uma URL segue este padrão: protocolo://subdomínio.domínio.extensão/caminho?parâmetros#fragmento. Cada um desses elementos é vital no processo de navegação, e componentes ausentes ou incorretos podem resultar em links quebrados ou conexões falhas.
| Componente da URL | Exemplo | Finalidade |
|---|---|---|
| Protocolo | https:// | Especifica o método de comunicação (HTTP ou HTTPS) |
| Subdomínio | www | Organiza seções diferentes de um site |
| Nome de Domínio | exemplo | O identificador único do site |
| Extensão (TLD) | .com | Domínio de topo indicando tipo/país do site |
| Caminho | /produtos/item | Especifica a localização exata da página ou recurso |
| Parâmetros | ?id=123&color=blue | Envia dados adicionais para o servidor |
| Fragmento | #section-2 | Aponta para uma seção específica dentro da página |
O protocolo é o primeiro componente crítico de qualquer URL. O HTTPS (Protocolo de Transferência de Hipertexto Seguro) tornou-se o padrão para sites modernos, substituindo o antigo protocolo HTTP. O HTTPS criptografa os dados transmitidos entre seu navegador e o servidor, protegendo informações sensíveis como senhas e números de cartão de crédito contra interceptação. Quando você vê um cadeado na barra de endereços, isso indica que a conexão é segura e criptografada. Essa camada de segurança é essencial para sites de e-commerce, bancos e qualquer site que lide com informações pessoais ou financeiras.
O nome de domínio é a parte mais reconhecível de uma URL e serve como identificador único do site. Ele é composto por um domínio de segundo nível (o nome escolhido, como “exemplo”) e um domínio de topo ou TLD (como .com, .org ou .net). O subdomínio, geralmente “www”, vem antes do nome de domínio e ajuda a organizar diferentes seções do site. Alguns sites usam subdomínios personalizados como “blog.exemplo.com” ou “suporte.exemplo.com” para separar áreas funcionais. O componente caminho especifica a localização exata de um recurso no servidor, usando barras para denotar pastas, semelhante à organização de arquivos no computador.
Configure o rastreamento avançado em minutos. Não é necessário cartão de crédito.
Ao clicar em um hyperlink ou digitar uma URL na barra de endereços, inicia-se um processo sofisticado que envolve múltiplos sistemas trabalhando em conjunto. Compreender esse processo revela por que os links funcionam dessa forma e por que certos erros podem ocorrer. Toda a jornada, desde clicar no link até visualizar a página, normalmente é concluída em poucos segundos, mas envolve várias etapas distintas que precisam ocorrer perfeitamente para o sucesso.
Passo 1: Ação do Usuário e Análise da URL – O processo começa quando você clica em um hyperlink ou digita manualmente uma URL no navegador. O navegador imediatamente analisa a URL, separando-a em suas partes: protocolo, nome de domínio, caminho, parâmetros e fragmentos. Essa análise é crítica, pois o navegador precisa entender cada componente para saber como proceder. Se a URL contiver erros de sintaxe ou caracteres inválidos, o navegador pode rejeitá-la ou tentar corrigir automaticamente.
Passo 2: Identificação do Protocolo – O navegador examina o protocolo especificado na URL (geralmente HTTPS ou HTTP) para determinar como estabelecer a conexão com o servidor. O protocolo define as regras de comunicação entre navegador e servidor web. Conexões HTTPS exigem etapas adicionais de segurança para criar um túnel criptografado, enquanto conexões HTTP são mais simples, porém menos seguras. Navegadores modernos alertam os usuários ao visitar sites HTTP, incentivando a adoção do HTTPS.
Passo 3: Resolução de DNS – Este é talvez o passo mais crucial do funcionamento dos links. O navegador precisa traduzir o nome de domínio legível (como www.exemplo.com ) em um endereço IP numérico compreendido pelos computadores. Essa tradução acontece pelo Sistema de Nomes de Domínio (DNS), uma rede distribuída de servidores que mantém um vasto banco de dados de nomes de domínio e endereços IP correspondentes. O navegador envia uma consulta DNS a um resolvedor, que busca pelo DNS até encontrar o servidor de nomes autoritativo do domínio. Uma vez encontrado, o resolvedor recupera o endereço IP e o retorna ao navegador. Esse processo dura milissegundos, mas é essencial para estabelecer a conexão.
Passo 4: Conexão com o Servidor – De posse do endereço IP, o navegador estabelece uma conexão com o servidor que hospeda o site. Para conexões HTTPS, isso envolve um handshake TLS (Segurança da Camada de Transporte), onde navegador e servidor trocam chaves criptográficas para garantir uma comunicação segura. Esse handshake verifica a identidade do servidor por meio de certificados digitais e garante que toda a comunicação subsequente seja criptografada. Para conexões HTTP, o navegador simplesmente estabelece uma conexão TCP na porta 80 (ou 443 para HTTPS).
Passo 5: Requisição HTTP – Uma vez estabelecida a conexão, o navegador envia uma requisição HTTP ao servidor, especificando qual recurso deseja obter. Essa requisição inclui o caminho da URL, parâmetros, strings de consulta e cabeçalhos com informações sobre o navegador, idioma preferido e outros dados. O servidor recebe a requisição e a processa, determinando qual arquivo ou recurso enviar ao navegador.
Passo 6: Resposta do Servidor – O servidor processa a requisição e envia uma resposta HTTP contendo o recurso solicitado. Essa resposta inclui um código de status (como 200 para sucesso, 404 para não encontrado ou 500 para erro do servidor), cabeçalhos com informações sobre o conteúdo e o próprio conteúdo (HTML, CSS, JavaScript, imagens etc.). O servidor pode também definir cookies ou outras informações de rastreamento nos cabeçalhos.
Passo 7: Renderização do Conteúdo – O navegador recebe a resposta e começa a renderizar o conteúdo. Ele analisa o HTML para entender a estrutura da página, aplica estilos CSS para formatar o conteúdo e executa o JavaScript para adicionar interatividade. Se a página faz referência a recursos externos (imagens, estilos, scripts), o navegador faz requisições adicionais para obtê-los. Esse processo continua até que todos os recursos sejam carregados e a página esteja totalmente exibida e interativa.
O Sistema de Nomes de Domínio (DNS) é a infraestrutura invisível que faz com que os links de sites funcionem, traduzindo nomes de domínio em endereços IP. Sem o DNS, os usuários precisariam memorizar longas sequências numéricas em vez de nomes simples como “exemplo.com”. O DNS opera como um sistema hierárquico e distribuído, com várias camadas de servidores trabalhando juntos para resolver nomes de domínio. Ao inserir uma URL no navegador, o processo de resolução DNS começa imediatamente, e o navegador não pode prosseguir até receber o endereço IP do domínio.
O processo de resolução DNS envolve vários tipos de servidores atuando em conjunto. O navegador primeiro contata um resolvedor recursivo, normalmente fornecido pelo provedor de internet (ISP) ou por um serviço público como Google DNS ou Cloudflare DNS. Esse resolvedor é responsável por encontrar a resposta à consulta DNS, consultando outros servidores se necessário. Se o resolvedor não tiver a resposta em cache, ele consulta um servidor raiz, que o direciona ao servidor de nomes do domínio de topo (TLD). O servidor TLD então direciona ao servidor autoritativo do domínio, que finalmente fornece o endereço IP. Todo esse processo, chamado de recursão DNS, ocorre de forma transparente e geralmente leva apenas milissegundos.
O cache de DNS tem papel crucial na eficiência dos links de sites. Assim que um resolvedor obtém o endereço IP de um domínio, ele armazena essa informação por um período definido pelo valor TTL (Time To Live) do domínio. Isso evita a realização de uma busca DNS completa a cada visita, acelerando significativamente o acesso. O navegador também mantém seu próprio cache de DNS, assim como os ISPs e outros resolvedores espalhados pela internet. Esse sistema de cache em múltiplos níveis garante que sites populares possam ser acessados rapidamente, sem precisar consultar repetidamente os servidores autoritativos.
Seja o primeiro a saber sobre novos recursos e atualizações do produto.
O protocolo especificado no início da URL determina como o navegador se comunica com o servidor web. O HTTP (Protocolo de Transferência de Hipertexto) foi o protocolo original da web, mas transmitia dados em texto simples, sem criptografia. Isso significava que qualquer pessoa interceptando a conexão poderia ler informações sensíveis, como senhas ou números de cartão. O HTTPS (HTTP Seguro) resolve essa vulnerabilidade acrescentando uma camada de criptografia por meio de certificados SSL/TLS (Camada de Soquete Seguro/Segurança da Camada de Transporte).
Ao acessar um site HTTPS, navegador e servidor realizam um handshake TLS para estabelecer uma conexão segura. Durante esse processo, o servidor apresenta um certificado digital que comprova sua identidade e contém uma chave pública. O navegador verifica a autenticidade do certificado consultando uma lista de Autoridades Certificadoras confiáveis. Uma vez verificado, navegador e servidor usam a chave pública para estabelecer uma chave de criptografia compartilhada, usada para proteger toda a comunicação subsequente. Assim, mesmo que alguém intercepte o tráfego, não conseguirá ler os dados transmitidos.
A diferença entre HTTP e HTTPS não é apenas sobre segurança; ela também afeta o ranqueamento em mecanismos de busca e a confiança do usuário. O Google e outros buscadores dão preferência a sites HTTPS nos resultados, e navegadores modernos exibem alertas ao visitar sites HTTP. Os usuários passaram a buscar o cadeado na barra de endereços como sinal de conexão segura, e muitos abandonam sites ao ver avisos de segurança. Por isso, o HTTPS tornou-se padrão para todos os sites, não apenas os que tratam dados sensíveis.
Os parâmetros de URL, também chamados strings de consulta, permitem que sites enviem informações adicionais ao servidor por meio da própria URL. Esses parâmetros aparecem após um ponto de interrogação (?) e consistem em pares chave-valor separados por “&”. Por exemplo, uma URL de busca pode ser https://www.exemplo.com/busca?q=links+de+site&categoria=tecnologia&ordem=relevancia. Cada parâmetro fornece informações específicas usadas pelo servidor para personalizar a resposta.
Os parâmetros de URL desempenham funções importantes no funcionamento dos links. Mecanismos de busca usam parâmetros para rastrear consultas e filtrar resultados. E-commerces utilizam para filtrar produtos por categoria, preço ou outros atributos. Ferramentas de análise usam parâmetros (os chamados parâmetros UTM) para rastrear a origem e a efetividade de campanhas de marketing. Parâmetros de paginação permitem exibir conjuntos grandes de dados em várias páginas. Sem os parâmetros, os sites seriam menos flexíveis e poderosos, incapazes de personalizar o conteúdo ou rastrear o comportamento do usuário com eficiência.
Porém, os parâmetros de URL também apresentam desafios para SEO e experiência do usuário. Mecanismos de busca podem tratar URLs com parâmetros diferentes como páginas distintas, criando problemas de conteúdo duplicado. URLs longas e cheias de parâmetros são difíceis de ler e compartilhar. Por esses motivos, práticas modernas de desenvolvimento web preferem estruturas de URL mais limpas usando caminhos em vez de parâmetros quando possível. Por exemplo, ao invés de exemplo.com/produtos?categoria=sapatos, um formato mais limpo seria exemplo.com/produtos/sapatos. Ainda assim, parâmetros são essenciais para conteúdo dinâmico e rastreamento.
Entender como funcionam os links de sites também significa compreender o que pode dar errado. O erro mais comum é o 404 Não Encontrado, que ocorre quando o servidor não encontra o recurso solicitado na URL informada. Isso pode acontecer se uma página foi excluída, movida ou se a URL contém um erro de digitação. Outros erros comuns incluem 403 Proibido (quando você não tem permissão para acessar o recurso), 500 Erro Interno do Servidor (quando há um problema inesperado) e 502 Gateway Inválido (quando o servidor recebe resposta inválida de outro servidor).
Ao encontrar um link quebrado, algumas etapas podem ajudar na solução. Primeiro, verifique cuidadosamente a URL em busca de erros de digitação ou maiúsculas indevidas. URLs diferenciam maiúsculas de minúsculas, então Exemplo.com e exemplo.com podem ser tratados de forma diferente em alguns servidores. Se a URL parecer correta, tente remover o caminho após o domínio para ver se o site principal está acessível. Se o site principal funcionar, mas a página específica não, ela pode ter sido movida ou excluída. Nesse caso, tente buscar o conteúdo em um mecanismo de busca, que pode levar à nova URL ou a uma versão arquivada.
Proprietários de sites podem evitar links quebrados implementando redirecionamentos apropriados quando URLs mudam. Um redirecionamento 301 (permanente) informa aos buscadores e navegadores que uma página foi movida definitivamente, preservando o ranqueamento e encaminhando automaticamente os usuários ao novo endereço. Um redirecionamento 302 (temporário) indica uma mudança provisória e não transfere autoridade de busca. Ao implementar redirecionamentos estrategicamente, é possível manter a experiência do usuário e o ranqueamento mesmo ao reestruturar o site.
Criar URLs eficazes exige entender como funcionam os links e considerar fatores técnicos e de experiência do usuário. As URLs devem ser descritivas e conter palavras-chave relevantes que indiquem o conteúdo da página. Por exemplo, exemplo.com/blog/como-otimizar-links-de-site é muito mais informativo do que exemplo.com/pagina123. URLs descritivas ajudam usuários e buscadores a entender o que esperar, melhorando a taxa de cliques nos resultados e tornando os links mais compartilháveis em redes sociais.
As URLs também devem ser as mais curtas possível, sem perder a clareza. URLs longas são difíceis de digitar, lembrar e compartilhar. Elas podem ser truncadas em resultados de busca ou postagens sociais, perdendo eficácia em campanhas de marketing. O uso de hífens para separar palavras é preferível a sublinhados ou outros caracteres, pois mecanismos de busca tratam hífens como separadores de palavras, mas podem não reconhecer sublinhados. Use sempre letras minúsculas para evitar confusões, já que alguns servidores diferenciam maiúsculas de minúsculas.
A estrutura das URLs deve refletir a organização lógica do conteúdo do site. Uma estrutura hierárquica como exemplo.com/produtos/eletronicos/notebooks/gamers indica claramente a relação entre as seções de conteúdo e ajuda o usuário a entender onde está no site. Essa estrutura também facilita o rastreamento e a indexação pelos buscadores. Ao planejar a estrutura de URLs, considere o crescimento do site e crie endereços que continuem relevantes e funcionais à medida que o conteúdo aumenta.
Fragmentos de URL, indicados por um símbolo de cerquilha (#) seguido de um identificador, permitem que links apontem para seções específicas dentro de uma página. Por exemplo, exemplo.com/artigo#secao-2 fará o navegador exibir a página e rolar automaticamente até a seção com ID “secao-2”. Fragmentos são processados inteiramente pelo navegador do lado do cliente e não são enviados ao servidor, sendo úteis para melhorar a experiência do usuário sem exigir processamento no servidor. Muitos sites modernos usam fragmentos para criar experiências dinâmicas do tipo “single page”, onde diferentes conteúdos podem ser acessados sem recarregar a página inteira.
Links âncora, criados com tags de âncora HTML e atributos ID, funcionam em conjunto com fragmentos de URL para permitir navegação precisa em páginas longas. Quando o usuário clica em um link âncora ou acessa uma URL com fragmento, o navegador rola automaticamente até o elemento correspondente. Essa funcionalidade é especialmente valiosa para conteúdos longos como artigos, documentações ou guias, onde se deseja ir direto a uma seção. Mecanismos de busca reconhecem e indexam links âncora, podendo exibir links diretos para seções específicas nos resultados de busca, melhorando o clique e a satisfação do usuário.
Deep linking refere-se à prática de criar links diretos para conteúdos internos de um site, em vez de apenas para a página inicial. Links profundos são essenciais para a experiência do usuário e o SEO, permitindo acesso rápido ao que se busca sem navegar por várias páginas. Buscadores favorecem sites com boas práticas de deep linking, pois isso indica uma arquitetura da informação bem organizada. Para afiliados e criadores de conteúdo, o deep linking é indispensável, pois direciona o tráfego para produtos, artigos ou recursos mais relevantes para seu público.
Para quem trabalha com marketing de afiliados, entender o funcionamento dos links de sites é essencial para gerenciar campanhas e acompanhar resultados. Links de afiliado são URLs especiais que incluem parâmetros de rastreamento que identificam o afiliado, a campanha e outras informações relevantes. Quando um usuário clica em um link de afiliado e realiza uma compra ou ação desejada, esses parâmetros permitem à rede de afiliados atribuir a conversão ao afiliado e campanha corretos. Essa atribuição é fundamental para o cálculo de comissões e análise de desempenho.
O PostAffiliatePro, principal plataforma de software para afiliados, oferece ferramentas avançadas para criação, gestão e rastreamento de links de afiliado. A plataforma permite gerar links personalizados com parâmetros de rastreamento embutidos, monitorar taxas de cliques e conversões em tempo real e otimizar campanhas a partir de análises detalhadas. O sistema sofisticado de gerenciamento de links do PostAffiliatePro garante rastreamento preciso em múltiplos canais e dispositivos, proporcionando aos afiliados os dados necessários para maximizar seus ganhos. O encurtamento de URLs facilita o compartilhamento dos links em redes sociais e outros canais, sem perder a capacidade de rastreamento.
Entender a estrutura das URLs e os parâmetros é especialmente importante para afiliados que utilizam o PostAffiliatePro. A plataforma permite personalizar os parâmetros de rastreamento para capturar informações específicas sobre as fontes de tráfego, campanhas e comportamento dos usuários. Ao usar estrategicamente os parâmetros, os afiliados podem segmentar o tráfego e identificar quais campanhas e canais são mais lucrativos. Essa abordagem orientada por dados permite a otimização contínua e a melhora dos resultados, levando a maiores ganhos e melhor retorno sobre o investimento.
Domine a gestão e o rastreamento de links com o software de afiliados líder do mercado. O PostAffiliatePro oferece rastreamento avançado de URLs, gerenciamento de links e análises completas para maximizar sua performance em marketing de afiliados.
Aprenda como criar hiperlinks em HTML com a tag <a>. Domine atributos href, URLs absolutas e relativas, boas práticas de links e técnicas avançadas de vinculaçã...
Hiperlink é uma palavra, texto ou imagem em uma página da web ou em um documento, que pode ser clicada. Saiba mais sobre os diferentes tipos de hiperlinks.
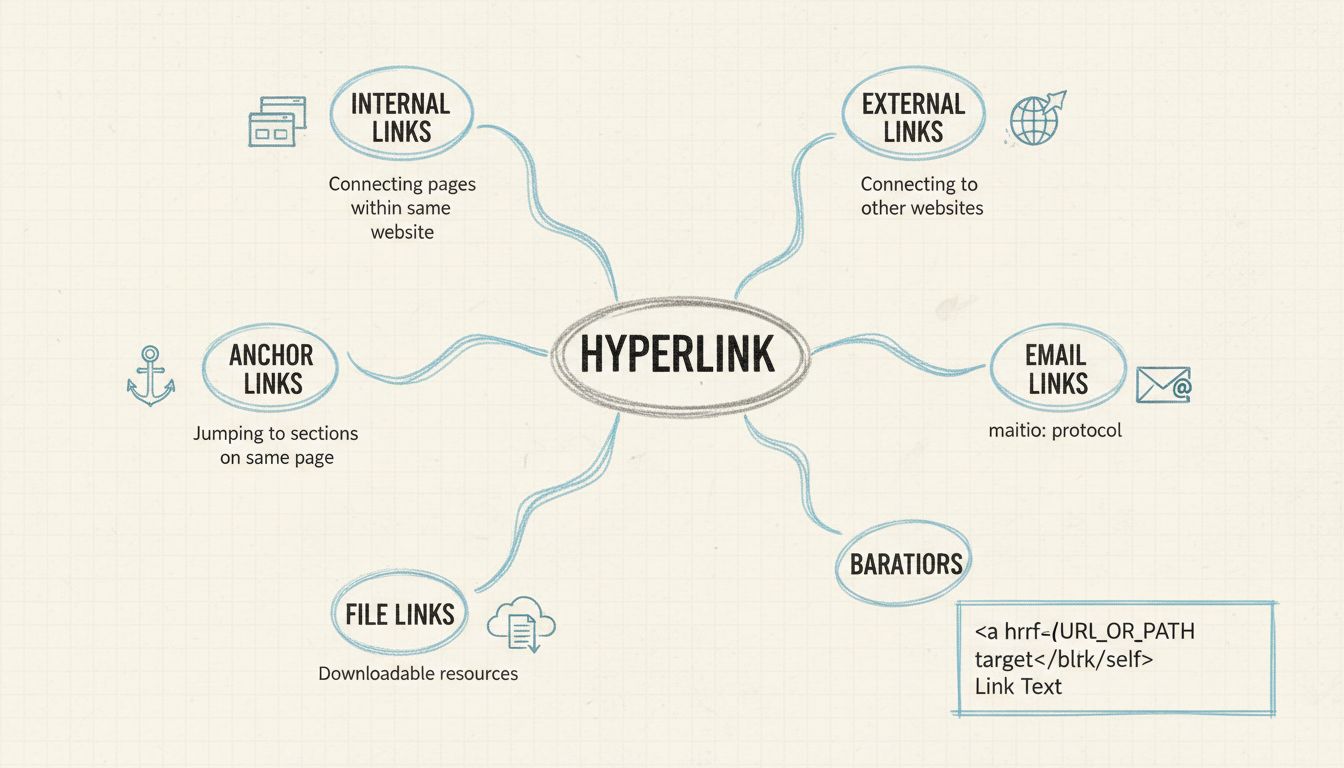
Descubra por que os hiperlinks são essenciais para páginas da web. Saiba como eles melhoram a navegação, SEO, engajamento do usuário e acessibilidade. Guia comp...
Junte-se à nossa comunidade de clientes satisfeitos e forneça excelente suporte ao cliente com o Post Affiliate Pro.
See our privacy policy.