
Crawlers e Seu Papel no Ranqueamento em Mecanismos de Busca
Crawlers acumulam dados e informações da internet visitando sites e lendo páginas. Descubra mais sobre eles.
6
SEO
Crawlers
+4
Descubra como funcionam os web crawlers, desde URLs iniciais até a indexação. Entenda o processo técnico, tipos de crawlers, regras do robots.txt e como eles impactam o SEO e o marketing de afiliados.
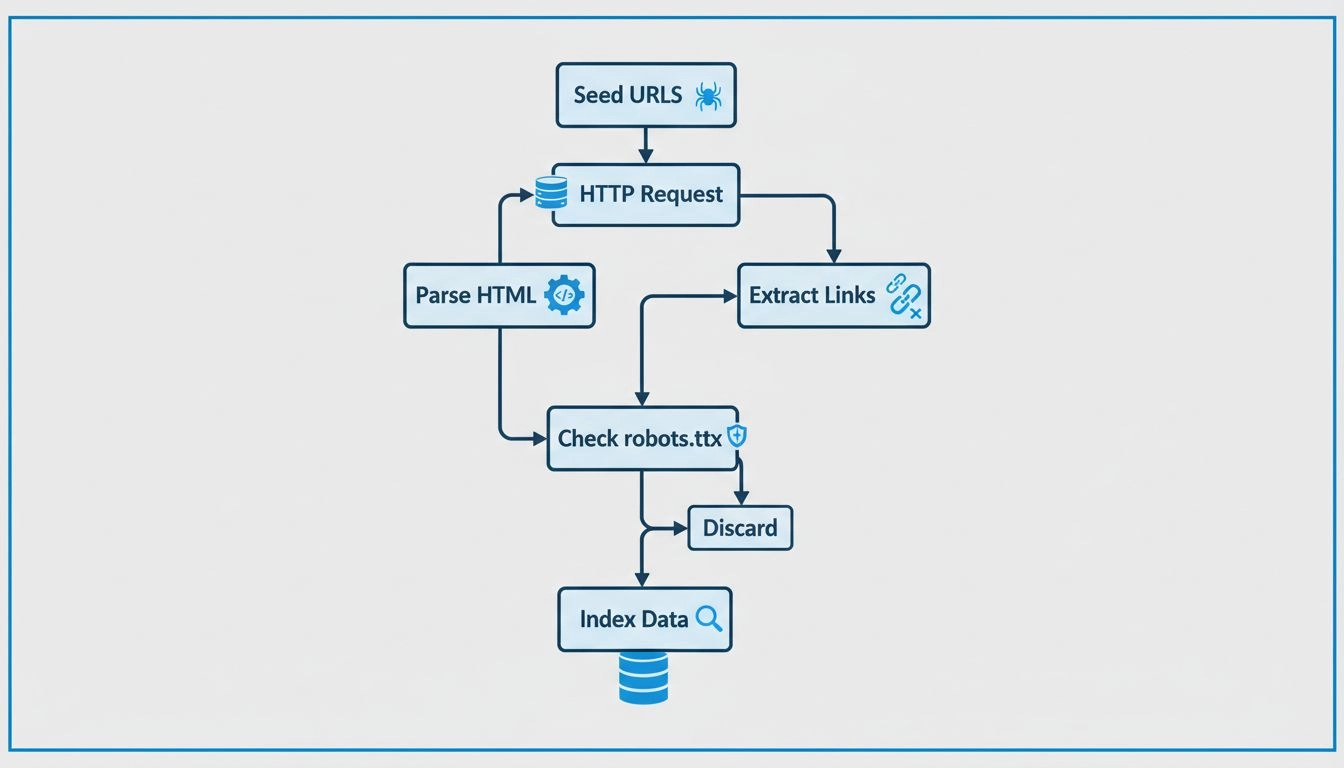
Web crawlers funcionam enviando requisições HTTP para sites a partir de URLs semente, seguindo hiperlinks para descobrir novas páginas, analisando o conteúdo HTML para extrair informações, respeitando as regras do robots.txt e armazenando os dados coletados em índices pesquisáveis. Eles visitam páginas sistematicamente, extraem metadados e links, e repetem o processo para manter os bancos de dados dos mecanismos de busca atualizados.
Web crawlers, também conhecidos como spiders ou bots, são programas automatizados que navegam sistematicamente pela internet para descobrir, baixar e analisar conteúdos de sites. Esses agentes inteligentes formam a espinha dorsal da infraestrutura dos mecanismos de busca, permitindo que plataformas como Google, Bing e outros serviços de pesquisa construam índices abrangentes de bilhões de páginas web. O principal objetivo dos web crawlers é coletar e organizar informações dos sites para que os mecanismos de busca possam recuperar rapidamente resultados relevantes quando os usuários realizam pesquisas. Sem os web crawlers, os mecanismos de busca não teriam como descobrir novos conteúdos ou manter seus índices atualizados com as informações mais recentes disponíveis online.
A importância dos web crawlers vai muito além da simples funcionalidade de busca. Eles servem como base para diversas aplicações digitais, incluindo sites de comparação de preços, agregadores de conteúdo, plataformas de pesquisa de mercado, ferramentas de análise de SEO e serviços de arquivamento web. Para profissionais de marketing de afiliados e operadores de redes como os que utilizam o PostAffiliatePro, compreender como funcionam os crawlers é essencial para garantir que conteúdos de afiliados, páginas de produtos e materiais promocionais sejam devidamente descobertos e indexados pelos mecanismos de busca. Essa visibilidade impacta diretamente o tráfego orgânico, a geração de leads e, em última análise, as oportunidades de comissão dos afiliados.
Os web crawlers seguem um processo metódico e estruturado para explorar a internet de forma sistemática. O processo começa com URLs semente, que são pontos de partida conhecidos, como endereços de páginas iniciais, sitemaps em XML ou páginas previamente rastreadas. Essas URLs semente servem como ponto de entrada para a jornada do crawler pela web. O crawler mantém uma fila de URLs a serem visitadas, frequentemente chamada de “fronteira de rastreamento”, que cresce continuamente à medida que novos links são descobertos durante o processo.
Quando um crawler chega a uma URL, ele envia uma requisição HTTP para o servidor web que hospeda aquela página. O servidor responde enviando o conteúdo HTML da página, de forma semelhante ao carregamento feito por um navegador ao acessá-la. O crawler então analisa esse código HTML para extrair informações valiosas, incluindo o conteúdo textual, meta tags (como título e descrição), imagens, vídeos e, principalmente, hiperlinks para outras páginas. Essa extração de links é fundamental porque permite ao crawler descobrir novas URLs ainda não visitadas, que são então adicionadas à fila de rastreamento para visitas futuras.
| Etapa do Processo do Crawler | Descrição | Ações Principais |
|---|---|---|
| Inicialização | Início do processo de rastreamento | Carregar URLs semente, inicializar fila de rastreamento |
| Requisição & Recuperação | Busca do conteúdo da página | Enviar requisições HTTP, receber respostas HTML |
| Análise do HTML | Parsing da estrutura da página | Extrair texto, metadados, links, mídias |
| Extração de Links | Encontrar novas URLs | Identificar hiperlinks, adicionar à fila de rastreamento |
| Verificação do robots.txt | Respeitar as regras do site | Verificar permissões de rastreamento antes de visitar |
| Armazenamento do Conteúdo | Salvar informações | Indexar dados em banco pesquisável |
| Priorização | Determinar próximas páginas | Classificar URLs por importância e relevância |
| Repetição | Continuar o ciclo | Processar próxima URL na fila |
Antes de visitar uma nova URL em um domínio, crawlers responsáveis verificam o arquivo robots.txt localizado no diretório raiz desse domínio. Esse arquivo contém instruções que os proprietários de sites usam para comunicar aos crawlers quais páginas podem ser rastreadas e quais devem ser evitadas. Por exemplo, um proprietário pode usar o robots.txt para impedir que crawlers acessem páginas sensíveis, conteúdos duplicados ou seções pesadas que possam sobrecarregar seus servidores. A maioria dos crawlers legítimos de mecanismos de busca respeita essas instruções para manter um bom relacionamento com os proprietários de sites e evitar problemas de desempenho.
Configure o rastreamento avançado em minutos. Não é necessário cartão de crédito.
Os web crawlers modernos evoluíram significativamente para lidar com a complexidade dos sites atuais. Muitos sites hoje utilizam JavaScript para gerar conteúdo dinamicamente após o carregamento da página, o que significa que a resposta HTML inicial não contém todo o conteúdo. Crawlers avançados agora usam navegadores headless para renderizar o JavaScript e capturar conteúdos carregados dinamicamente, que não seriam visíveis para crawlers tradicionais. Essa capacidade é essencial para rastrear aplicações de página única, dashboards interativos e aplicações modernas que dependem fortemente de renderização no lado do cliente.
Os crawlers implementam algoritmos sofisticados de priorização para utilizar de forma eficiente seu orçamento de rastreamento — o número limitado de páginas que podem rastrear em determinado período. Esses algoritmos consideram múltiplos fatores, incluindo autoridade da página (determinada pela qualidade e quantidade de backlinks), estrutura de links internos, atualidade do conteúdo, volume de tráfego e reputação do domínio. Páginas de alta autoridade e conteúdos frequentemente atualizados recebem visitas mais frequentes, enquanto páginas menos importantes ou estáticas podem ser visitadas com menor frequência ou até ignoradas. Essa priorização inteligente garante que os crawlers concentrem seus recursos nos conteúdos mais valiosos e dinâmicos.
Delay de rastreamento e limitação de taxa são mecanismos importantes para evitar que crawlers sobrecarreguem servidores web. Crawlers responsáveis implementam pausas entre requisições e respeitam as diretivas de crawl-delay especificadas nos arquivos robots.txt. Esse comportamento cortês protege o desempenho do site e a experiência dos usuários, garantindo que o tráfego dos crawlers não consuma recursos excessivos do servidor. Sites que carregam lentamente ou retornam erros podem ter sua frequência de rastreamento reduzida, já que os crawlers automaticamente diminuem o ritmo para evitar causar problemas.
Diferentes tipos de web crawlers servem a propósitos distintos no ecossistema digital. Crawlers gerais são utilizados pelos principais mecanismos de busca para rastrear toda a internet indiscriminadamente, criando índices abrangentes que alimentam os resultados de pesquisa. Esses crawlers são projetados para máxima cobertura e operam continuamente para descobrir novos conteúdos e atualizar os índices existentes. Crawlers verticais ou especializados focam em setores ou tipos específicos de conteúdo, como crawlers de vagas de emprego, crawlers de comparação de preços que coletam dados de e-commerces ou crawlers de pesquisa que indexam artigos acadêmicos e publicações científicas.
Crawlers incrementais são especialistas em eficiência, focando apenas em conteúdos novos ou recentemente modificados ao invés de rastrear repetidamente sites inteiros. Essa abordagem reduz significativamente a carga sobre os servidores e o consumo de banda, mantendo os índices relativamente atualizados. Crawlers focados utilizam algoritmos sofisticados para buscar conteúdos sobre tópicos ou palavras-chave específicas, priorizando inteligentemente páginas com maior probabilidade de conter informações relevantes. Crawlers em tempo real monitoram continuamente sites e atualizam seus dados coletados em tempo real ou quase em tempo real, sendo ideais para agregação de notícias e monitoramento de mídias sociais.
Crawlers paralelos e crawlers distribuídos representam o extremo da infraestrutura de rastreamento. Crawlers paralelos operam em múltiplas máquinas ou threads simultaneamente para aumentar drasticamente a velocidade e a capacidade de rastreamento. Crawlers distribuídos dividem o trabalho entre vários servidores ou datacenters, permitindo processar enormes volumes de dados de forma eficiente. Grandes mecanismos de busca como o Google utilizam arquiteturas de crawlers distribuídos para lidar com os bilhões de páginas na internet.
Seja o primeiro a saber sobre novos recursos e atualizações do produto.
Web crawlers desempenham um papel fundamental na otimização para mecanismos de busca, pois determinam quais páginas serão indexadas e como os mecanismos entendem seu conteúdo. Se os crawlers não conseguirem acessar suas páginas, elas não aparecerão nos resultados de pesquisa, independentemente de sua qualidade ou relevância. Problemas comuns de rastreamento que impedem a indexação adequada incluem páginas bloqueadas por diretivas do robots.txt, links internos quebrados que levam a erros 404, tempos de carregamento lentos que causam timeout dos crawlers e problemas de renderização de JavaScript que impedem a visualização de conteúdos dinâmicos.
Proprietários de sites podem otimizar o acesso dos crawlers através de diversas estratégias-chave. Arquitetura clara do site com hierarquias de navegação lógicas ajuda os crawlers a entenderem as relações e a importância das páginas. Links internos sinalizam quais páginas são mais importantes e ajudam a distribuir eficientemente o orçamento de rastreamento pelo site. Sitemaps XML listam explicitamente todas as páginas importantes, garantindo que os crawlers não percam conteúdos, mesmo em sites grandes ou complexos. Tempos de carregamento rápidos incentivam os crawlers a visitar mais páginas dentro do orçamento alocado, enquanto conteúdo fresco e regularmente atualizado sinaliza que o site merece visitas de rastreamento mais frequentes.
Para profissionais de marketing de afiliados que utilizam plataformas como o PostAffiliatePro, garantir o acesso adequado dos crawlers é fundamental para impulsionar o tráfego orgânico para conteúdos de afiliados. Quando suas páginas de produtos, artigos comparativos e conteúdos promocionais são devidamente rastreados e indexados, eles têm a chance de ranquear nos resultados de pesquisa e atrair tráfego qualificado. Uma baixa rastreabilidade pode resultar em oportunidades de indexação perdidas e visibilidade reduzida para suas ofertas de afiliados.
Proprietários de sites dispõem de vários mecanismos para controlar como os crawlers interagem com seus sites. O arquivo robots.txt é a principal ferramenta, contendo diretivas que especificam quais user-agents (tipos de crawlers) podem acessar quais partes do site. Um robots.txt bem configurado pode evitar que crawlers desperdicem recursos com conteúdos duplicados, ambientes de testes ou páginas pesadas, ao mesmo tempo que permite o rastreamento livre do conteúdo importante. A meta tag robots aparece no HTML de páginas individuais e oferece controle em nível de página, permitindo que páginas específicas sejam excluídas da indexação ou que seus links sejam ignorados.
O atributo de link nofollow instrui os crawlers a não seguirem determinados hiperlinks, sendo útil para evitar que rastreadores sigam links para sites externos não confiáveis ou conteúdos gerados por usuários. Esses mecanismos de controle trabalham juntos para dar aos proprietários de sites um controle detalhado sobre o comportamento dos crawlers, mantendo ao mesmo tempo um bom relacionamento com os mecanismos de busca. No entanto, é importante observar que scrapers maliciosos e bots agressivos frequentemente ignoram essas diretivas, motivo pelo qual medidas adicionais de segurança, como limitação de taxa e detecção de bots, às vezes são necessárias.
Para operadores de redes de afiliados e profissionais de marketing, compreender o comportamento dos web crawlers impacta diretamente o sucesso do negócio. Os crawlers determinam a visibilidade das páginas de produtos de afiliados, conteúdos comparativos e materiais promocionais nos resultados de busca. Quando usuários do PostAffiliatePro otimizam seus sites para o rastreamento adequado, aumentam as chances de que seus conteúdos sejam descobertos pelos mecanismos de busca e ranqueados para palavras-chave relevantes. Essa visibilidade orgânica atrai tráfego qualificado para as ofertas de afiliados, ampliando as oportunidades de conversão e os ganhos comissões.
As redes de afiliados se beneficiam da atividade dos crawlers de várias formas. Crawlers de mecanismos de busca ajudam a distribuir conteúdos de afiliados pela internet, aumentando o reconhecimento e o alcance da marca. Crawlers também possibilitam que sites de comparação de preços e agregadores de conteúdo descubram e destaquem produtos de afiliados, criando fontes adicionais de tráfego. No entanto, profissionais de afiliados também devem estar atentos a crawlers maliciosos e scrapers que podem copiar conteúdos de afiliados ou praticar fraudes de cliques. Implementar limitação de taxa, detecção de bots e proteção de conteúdo ajuda a preservar a integridade da rede de afiliados, ao mesmo tempo em que permite o funcionamento adequado dos crawlers legítimos.
O PostAffiliatePro oferece recursos completos de rastreamento e relatórios que complementam a otimização para crawlers. Ao garantir que seu conteúdo de afiliado seja devidamente rastreado e indexado, combinado com o rastreamento avançado e a análise do PostAffiliatePro, você pode maximizar a visibilidade e lucratividade da sua rede de afiliados. O rastreamento de comissões em tempo real e os relatórios inteligentes da plataforma ajudam a entender quais canais de afiliados geram o tráfego mais valioso, permitindo otimizar sua estratégia de rede de acordo.
Assim como os web crawlers descobrem e indexam conteúdos de forma sistemática, o PostAffiliatePro acompanha e otimiza sistematicamente seus relacionamentos de afiliados. Nossa plataforma oferece rastreamento em tempo real, relatórios completos e gestão inteligente de comissões para ajudar você a construir uma rede de afiliados de sucesso.
Crawlers acumulam dados e informações da internet visitando sites e lendo páginas. Descubra mais sobre eles.
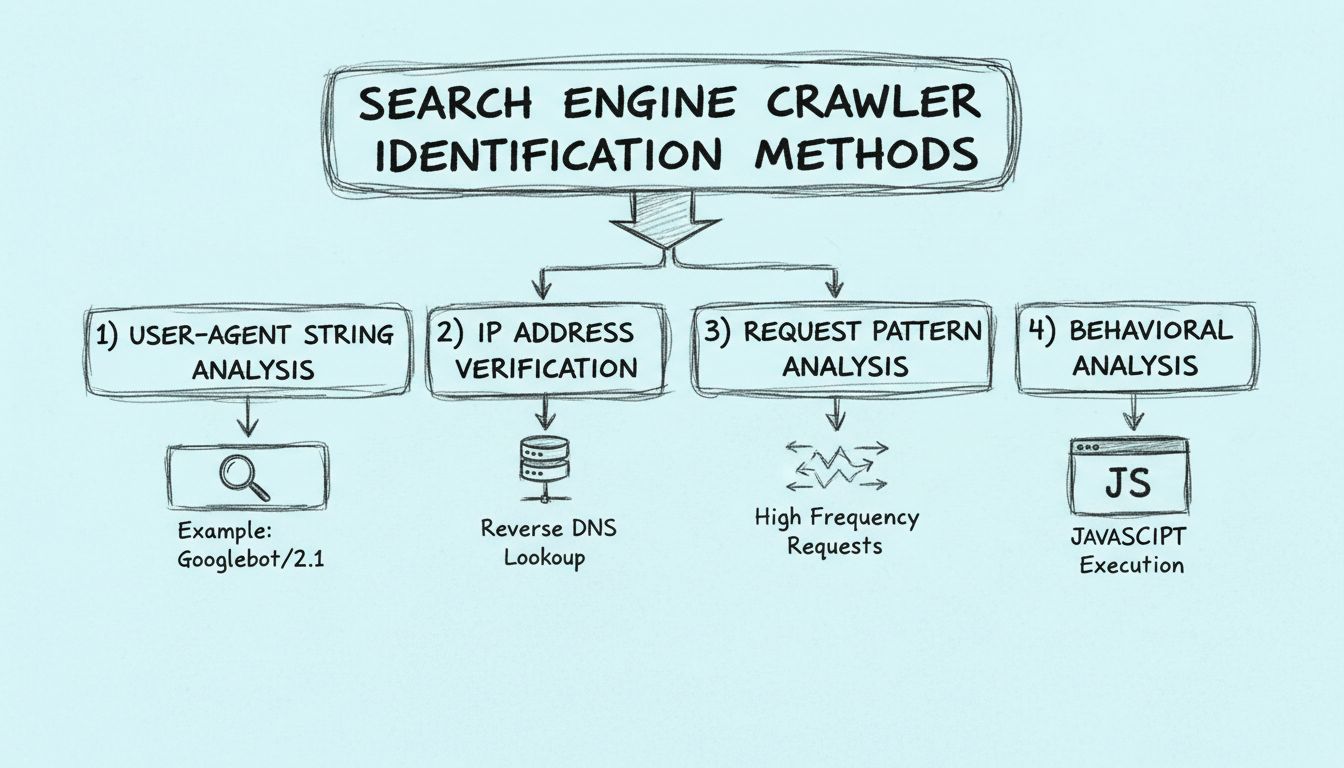
Aprenda como identificar crawlers de motores de busca utilizando strings de user-agent, endereços IP, padrões de requisição e análise comportamental. Guia essen...
Spiders são bots criados para spamming, que podem causar muitos problemas para o seu negócio. Saiba mais sobre eles no artigo.
Junte-se à nossa comunidade de clientes satisfeitos e forneça excelente suporte ao cliente com o Post Affiliate Pro.
See our privacy policy.