

Como verificar se seu site está indexado pelo Google
Aprenda 7 métodos comprovados para saber se seu site está indexado pelo Google. Use o Google Search Console, operadores de site, ferramentas de inspeção de URL ...
11
Saiba o que significa a indexação de páginas, por que páginas não são indexadas pelo Google e como corrigir problemas de indexação. Descubra soluções técnicas e melhores práticas para 2025.
Quando uma página não está indexada, significa que o mecanismo de busca não a adicionou ao seu banco de dados, então ela não aparecerá nos resultados de pesquisa. Isso pode acontecer devido a problemas técnicos como tags noindex ou bloqueios no robots.txt, erros de rastreamento, conteúdo duplicado, baixa qualidade ou simplesmente porque a página ainda não foi descoberta.
Quando uma página está “não indexada”, significa que o mecanismo de busca do Google não a adicionou ao seu banco de dados, tornando-a invisível nos resultados de pesquisa. Isso é fundamentalmente diferente de uma página que existe, mas simplesmente não tem bom posicionamento para palavras-chave específicas. Compreender a diferença entre indexação e ranqueamento é crucial para quem gerencia conteúdo online ou campanhas de marketing de afiliados. A indexação é o passo prévio e indispensável para que uma página tenha chance de aparecer nos resultados de busca. Sem indexação, seu conteúdo é essencialmente invisível para mecanismos de busca e para visitantes que dependem do Google para encontrar informações. O processo de indexação envolve três etapas fundamentais: rastreamento (quando o Googlebot visita sua página), indexação (quando a página é adicionada ao banco de dados do Google) e ranqueamento (quando a página aparece nos resultados para consultas relevantes).
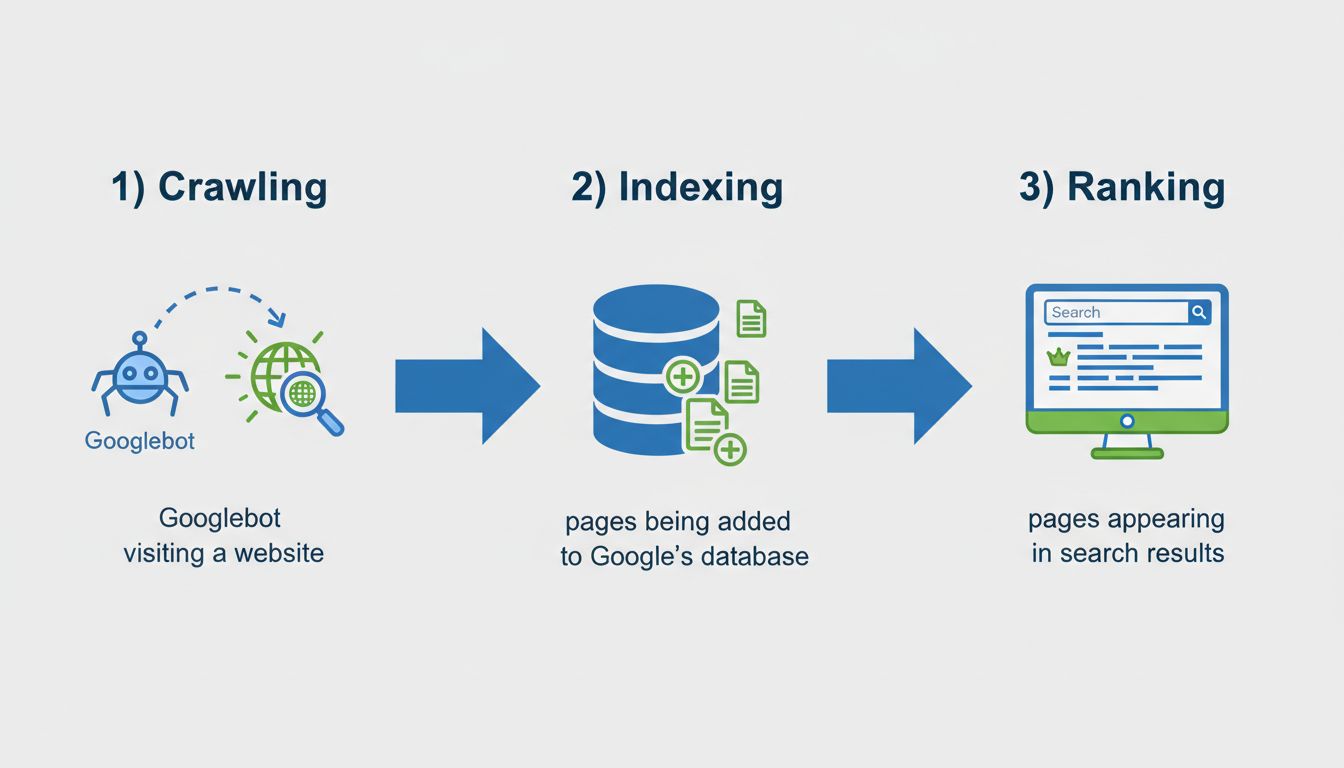
Existem inúmeros motivos para uma página não ser indexada, geralmente divididos em três categorias principais: problemas técnicos, problemas de qualidade de conteúdo e questões de descoberta. Entender cada categoria ajuda a diagnosticar e corrigir problemas de indexação de forma mais eficaz. As barreiras técnicas mais comuns incluem tags meta noindex, restrições do robots.txt, conflitos de tag canônica e erros de servidor. Problemas relacionados ao conteúdo geralmente envolvem conteúdo raso ou duplicado, baixa qualidade ou conteúdo que não corresponde à intenção de busca do usuário. Problemas de descoberta ocorrem quando o Google simplesmente não encontrou sua página ainda devido à falta de links internos, ausência no sitemap ou por ser uma página muito nova.
Tags Meta Noindex e Bloqueios no Robots.txt
Um dos motivos mais frequentes para páginas não indexadas é a presença da tag meta noindex. Essa diretiva HTML instrui explicitamente os mecanismos de busca a não indexarem uma página, mesmo que possam rastreá-la com sucesso. A tag aparece no código-fonte da página como <meta name="robots" content="noindex">. Às vezes, essas tags são adicionadas acidentalmente durante o desenvolvimento ou por plugins de SEO configurados incorretamente. Para verificar se sua página possui uma tag noindex, clique com o botão direito na página, selecione “Ver código-fonte da página” e procure por “noindex”. Você também pode usar a Ferramenta de Inspeção de URL do Google Search Console, que indicará claramente se uma página está bloqueada por uma tag noindex.
O arquivo robots.txt é outra barreira técnica crítica. Esse arquivo controla quais partes do seu site o Googlebot tem permissão para rastrear. Se páginas importantes estiverem bloqueadas no robots.txt com uma diretiva “Disallow”, o Google não conseguirá rastreá-las e, consequentemente, não irá indexá-las. Você pode verificar seu arquivo robots.txt acessando seudominio.com/robots.txt no navegador. Procure por linhas que começam com “Disallow” e verifique se seções importantes como /blog/ ou /produtos/ não estão bloqueadas por engano.
Configurações Incorretas de Tag Canônica
Tags canônicas informam ao Google qual versão de uma página deve ser indexada quando existem duplicatas. Se uma tag canônica aponta para a URL errada—como sua página inicial ou uma página completamente diferente—o Google pode ignorar a página que você deseja indexar. Cada página deve, idealmente, ter uma tag canônica auto-referenciando apontando para si mesma. Você pode verificar isso visualizando o código-fonte da página e procurando por link rel="canonical". Se a URL na tag canônica não corresponder à URL da página atual, esse é o problema.
Erros de Servidor e Códigos de Status HTTP
Quando o Googlebot tenta rastrear uma página e encontra erros de servidor (códigos de status 5xx) ou erros de página não encontrada (códigos 404), interpreta isso como um sinal de que a página não está disponível ou funcional. Se esses erros persistirem, o Google pode remover a página do índice completamente. Você pode verificar erros de rastreamento no Google Search Console no relatório “Cobertura”, que mostra páginas com códigos de status HTTP problemáticos.
Conteúdo Raso e de Baixa Qualidade
O Google prioriza cada vez mais a qualidade e relevância do conteúdo. Páginas com conteúdo raso—ou seja, que carecem de profundidade, detalhes ou valor—são frequentemente excluídas do índice. Isso inclui páginas com pouquíssimas palavras, informações genéricas ou conteúdo que não responde adequadamente às dúvidas dos usuários. Os algoritmos do Google avaliam se o conteúdo oferece valor genuíno aos usuários. Se uma página contém informações desatualizadas, carece de insights originais ou simplesmente repete informações já disponíveis, o Google pode determinar que não vale a pena indexar.
Problemas de Conteúdo Duplicado
Quando várias páginas do seu site contêm conteúdo idêntico ou quase idêntico, o Google normalmente indexa apenas uma versão e marca as demais como duplicadas. Isso é comum com descrições de produtos copiadas de fornecedores, postagens de blog com variações mínimas ou páginas de serviços repetidas para diferentes localidades. Conteúdo duplicado também desperdiça seu orçamento de rastreamento, pois o Googlebot precisa gastar recursos identificando duplicatas em vez de rastrear conteúdo novo e exclusivo.
Desalinhamento com a Intenção de Busca
Páginas que não correspondem à intenção de busca dos usuários são frequentemente excluídas da indexação. Por exemplo, se você cria uma página sobre “ferramentas de SEO” mas a página é, na verdade, um post de blog e não uma comparação de ferramentas (que é o que a maioria dos usuários espera), o Google pode determinar que a página não é relevante para essa consulta e não a indexar. Entender a intenção de busca analisando os resultados mais bem posicionados antes de criar conteúdo é essencial.
Páginas Órfãs e Links Internos
Páginas sem links internos apontando para elas são chamadas de “páginas órfãs”. Se uma página não é vinculada de nenhum lugar do seu site e não está no sitemap, o Google pode nunca descobri-la. Mesmo que o Google a encontre, a falta de links internos sinaliza que a página não é importante, o que pode resultar em sua não indexação. Links internos funcionam como caminhos para o Googlebot descobrir conteúdo e também transmitem sinais de autoridade e relevância.
Ausência no Sitemap
Um sitemap é um arquivo que lista as páginas importantes do seu site, ajudando o Google a descobri-las e priorizá-las para rastreamento. Se uma página não está incluída no seu sitemap, fica mais difícil para o Google encontrá-la—especialmente se ela também não possui links internos. Embora páginas possam ser indexadas mesmo sem estarem no sitemap, a inclusão melhora significativamente a descoberta.
Limitações de Orçamento de Rastreamento
Sites grandes possuem um “orçamento de rastreamento” limitado—o número de páginas que o Google irá rastrear em determinado período. Se seu site tem muitas páginas de baixa qualidade, carregamento lento ou excesso de conteúdo duplicado, o Google pode alocar menos recursos para rastreá-lo. Isso significa que algumas páginas podem não ser rastreadas e indexadas rapidamente, ou nem sequer serem indexadas.
Configure o rastreamento avançado em minutos. Não é necessário cartão de crédito.
O Google Search Console é a principal ferramenta para diagnosticar por que páginas não são indexadas. A plataforma fornece relatórios detalhados mostrando exatamente quais páginas estão indexadas e por que outras não. Para acessar essas informações, acesse sua propriedade no Search Console, clique em “Indexação” no menu à esquerda e selecione “Páginas”. Esse relatório mostra suas páginas indexadas e fornece uma divisão das páginas não indexadas por motivo.
| Tipo de Problema | Status no GSC | O que significa | Solução |
|---|---|---|---|
| Tag Noindex | Excluída por tag ’noindex' | Página com diretiva noindex | Remover a tag noindex da página |
| Bloqueio no Robots.txt | Bloqueada pelo robots.txt | Página proibida no robots.txt | Atualizar o robots.txt para permitir rastreamento |
| Conteúdo Duplicado | Duplicada sem canônica selecionada pelo usuário | Múltiplas páginas semelhantes | Adicionar tags canônicas ou consolidar conteúdo |
| Baixa Qualidade | Descoberta – atualmente não indexada | Página com valor considerado baixo | Melhorar a profundidade e qualidade do conteúdo |
| Não Descoberta | Descoberta – atualmente não indexada | Página ainda não rastreada | Adicionar links internos e enviar sitemap |
| Erro de Servidor | Anomalia de rastreamento | Servidor retornou erro | Corrigir problemas no servidor e reenviar |
A Ferramenta de Inspeção de URL é outro recurso poderoso. Basta colar uma URL específica na barra de pesquisa no topo do Search Console, e o Google mostrará se aquela página está indexada, quando foi rastreada pela última vez e quaisquer problemas que estejam impedindo a indexação. Se uma página não estiver indexada, a ferramenta explica o motivo e, frequentemente, fornece um botão “Solicitar Indexação” para pedir ao Google que rastreie a página novamente.
Removendo Barreiras Técnicas
Comece resolvendo os problemas técnicos. Se sua página possui uma tag noindex e você deseja que ela seja indexada, remova a tag do HTML da página. No WordPress, isso normalmente é feito através do seu plugin de SEO (Yoast, Rank Math, All in One SEO) desmarcando a opção “Permitir que mecanismos de busca indexem esta página”. Se a página está bloqueada no robots.txt, atualize seu arquivo robots.txt para permitir o rastreamento daquela seção. Para problemas de tag canônica, certifique-se de que cada página tenha uma tag canônica auto-referenciada apontando para si mesma.
Melhorando a Qualidade do Conteúdo
Se sua página está marcada como “Descoberta – atualmente não indexada” ou “Rastreada – atualmente não indexada”, o problema provavelmente está na qualidade do conteúdo. Expanda o conteúdo para fornecer informações mais abrangentes, adicione insights ou dados originais, garanta que ele corresponda à intenção de busca e remova quaisquer conteúdos duplicados. Certifique-se de que sua página realmente responda às perguntas que os usuários estão fazendo ao pesquisar termos relacionados.
Aprimorando o Link Interno
Adicione links internos de páginas relevantes do seu site para a página não indexada. Esses links devem usar texto âncora descritivo e ser inseridos naturalmente no conteúdo. Busque adicionar de 2 a 5 links internos por página. Além disso, certifique-se de que a página está incluída no seu sitemap XML e que o sitemap está enviado ao Google Search Console.
Solicitando Indexação
Após fazer as correções, utilize a Ferramenta de Inspeção de URL no Google Search Console para solicitar indexação. O Google irá rastrear a página novamente e reavaliar se ela deve ser indexada. Embora não haja um prazo garantido, as páginas normalmente são rastreadas novamente em alguns dias até algumas semanas.
Seja o primeiro a saber sobre novos recursos e atualizações do produto.
Manter a boa saúde de indexação exige atenção contínua. Faça auditorias regulares usando o Google Search Console para monitorar o status de indexação. Certifique-se de que seu arquivo robots.txt esteja corretamente configurado e não bloqueie acidentalmente conteúdo importante. Implemente tags canônicas adequadas em todo o site, especialmente se você possui múltiplas versões de conteúdo semelhante. Mantenha práticas consistentes de linkagem interna, conectando conteúdos relacionados para ajudar o Google a entender a estrutura do seu site. Por fim, foque em criar conteúdo de alta qualidade e original, que forneça valor genuíno para seu público. Esta é a estratégia de longo prazo mais eficaz para garantir que suas páginas sejam indexadas e ranqueadas.
Acompanhe e gerencie suas campanhas de afiliados de forma eficaz com o monitoramento e análise avançados do PostAffiliatePro. Garanta que seu conteúdo alcance o público certo e maximize sua receita de afiliados com nossa plataforma líder no setor.
Aprenda 7 métodos comprovados para saber se seu site está indexado pelo Google. Use o Google Search Console, operadores de site, ferramentas de inspeção de URL ...
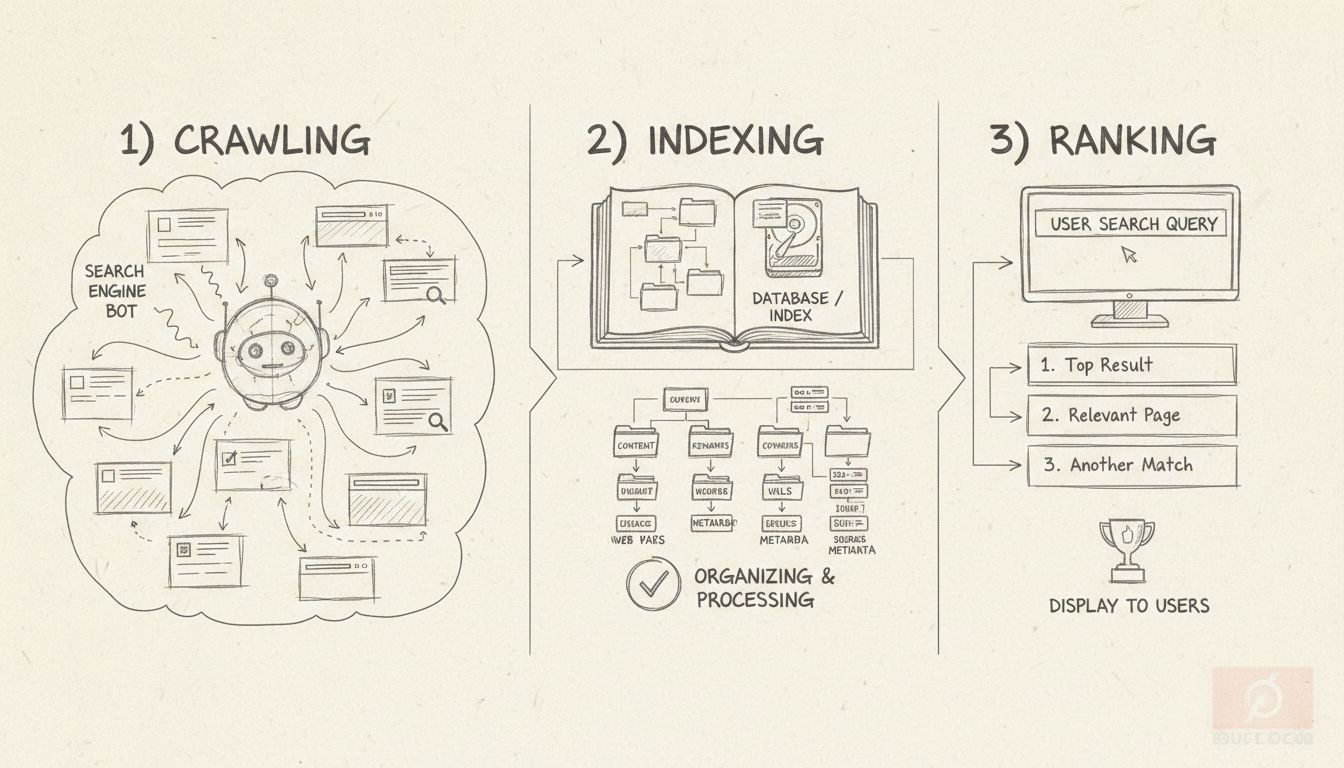
Saiba o que significa indexação em SEO, como funciona e por que é fundamental para a visibilidade de busca do seu site. Descubra as melhores práticas para garan...
A indexação é um processo em que uma determinada página da web é encontrada por rastreadores. Sinais-chave são notados e todos os dados são rastreados no índice...
Junte-se à nossa comunidade de clientes satisfeitos e forneça excelente suporte ao cliente com o Post Affiliate Pro.
See our privacy policy.