
Crawlers e Seu Papel no Ranqueamento em Mecanismos de Busca
Crawlers acumulam dados e informações da internet visitando sites e lendo páginas. Descubra mais sobre eles.
6
SEO
Crawlers
+4
Aprenda como identificar crawlers de motores de busca utilizando strings de user-agent, endereços IP, padrões de requisição e análise comportamental. Guia essencial para webmasters e desenvolvedores.
Crawlers de motores de busca podem ser identificados por quatro métodos principais: analisando a string user-agent nos cabeçalhos HTTP, verificando o endereço IP de origem e o hostname reverso DNS, monitorando padrões de requisição para acessos em alta frequência e examinando características comportamentais como a capacidade de execução de JavaScript.
Crawlers de motores de busca são programas automatizados que navegam sistematicamente pela internet para descobrir, analisar e indexar conteúdos da web. Identificar esses crawlers é crucial para webmasters, desenvolvedores e afiliados que precisam entender os padrões de tráfego dos seus sites e garantir o acesso legítimo dos motores de busca. Diferente de bots maliciosos que tentam extrair dados ou lançar ataques, crawlers legítimos como Googlebot, Bingbot e outros se identificam por meio de marcadores técnicos específicos que podem ser verificados e autenticados.
A capacidade de diferenciar crawlers legítimos de motores de busca de outros tipos de bots tornou-se ainda mais importante em 2025, à medida que o tráfego web cresce e a atividade de bots se torna mais sofisticada. Compreender os métodos de identificação ajuda a otimizar o rastreamento do seu site, proteger seus recursos contra acessos não autorizados e garantir que seus sistemas de rastreamento de afiliados distingam corretamente entre tráfego orgânico de busca e outras fontes. O PostAffiliatePro oferece recursos avançados de análise que ajudam a monitorar e categorizar fontes de tráfego com precisão, garantindo que seu programa de afiliados capture dados de desempenho confiáveis.
O método mais direto para identificar crawlers de motores de busca é examinar a string User-Agent no cabeçalho da requisição HTTP. Toda requisição HTTP inclui um cabeçalho User-Agent que identifica o cliente que faz a requisição, seja um navegador, aplicativo móvel ou crawler. Crawlers legítimos de motores de busca incluem identificadores distintos em suas strings User-Agent que deixam claro sua origem e propósito. Por exemplo, o crawler do Google se identifica como “Googlebot/2.1 (+http://www.google.com/bot.html)”, enquanto o crawler do Bing da Microsoft usa “Bingbot/2.0 (+http://www.bing.com/bingbot.htm)”.
Ao analisar as strings User-Agent, procure por padrões e palavras-chave específicas que indiquem crawlers legítimos. A string User-Agent normalmente contém o nome do crawler, o número da versão e um link para a documentação ou página de informações do crawler. Crawlers legítimos de grandes motores de busca como Google, Bing, Yahoo e Yandex seguem convenções de nomenclatura consistentes e incluem informações verificáveis sobre seu propósito. Você pode registrar essas strings User-Agent nos logs de acesso do seu servidor e compará-las com identificadores conhecidos mantidos por motores de busca e organizações de segurança.
| Nome do Crawler | Exemplo de String User-Agent | Motor de Busca |
|---|---|---|
| Googlebot | Googlebot/2.1 (+http://www.google.com/bot.html) | |
| Bingbot | Bingbot/2.0 (+http://www.bing.com/bingbot.htm) | Microsoft Bing |
| Slurp | Slurp/cat (+http://help.yahoo.com/help/us/ysearch/slurp) | Yahoo |
| Yandexbot | Mozilla/5.0 (compatible; YandexBot/3.0) | Yandex |
| DuckDuckBot | DuckDuckBot/1.0 (+http://duckduckgo.com/duckduckbot.html) | DuckDuckGo |
No entanto, depender apenas das strings User-Agent para identificar crawlers tem limitações. Bots maliciosos podem falsificar essas strings para se passarem por crawlers legítimos, tornando essencial combinar esse método com técnicas adicionais de verificação. Além disso, alguns crawlers legítimos podem usar strings User-Agent genéricas ou modificadas em certas situações, portanto, cruzar com outros métodos de identificação traz resultados mais confiáveis.
Configure o rastreamento avançado em minutos. Não é necessário cartão de crédito.
O segundo método fundamental para identificar crawlers de motores de busca envolve verificar o endereço IP de origem e realizar um lookup DNS reverso. Quando um crawler faz uma requisição ao seu servidor, ela parte de um endereço IP específico que pode ser registrado e analisado. Os motores de busca publicam faixas de endereços IP utilizadas por seus crawlers, permitindo aos webmasters verificar se uma requisição realmente parte da infraestrutura daquele motor de busca. O Google, por exemplo, mantém uma lista abrangente de endereços IP usados pelo Googlebot e outros crawlers do Google.
O lookup DNS reverso é uma técnica de verificação particularmente eficaz que consiste em consultar o sistema DNS para determinar o hostname associado a um endereço IP. Ao realizar um lookup reverso de um IP que alega ser do Google, ele deve resolver para um hostname dentro do domínio do Google (como “crawl-66-249-64-1.googlebot.com”). Esse hostname pode então ser verificado por meio de um lookup DNS direto para confirmar se ele resolve para o mesmo endereço IP, criando uma cadeia de verificação bidirecional. Esse processo de verificação em duas etapas dificulta muito a falsificação por parte de agentes maliciosos, pois eles precisariam controlar tanto o endereço IP quanto os registros DNS associados.
A documentação oficial do Google recomenda esse método de verificação como a forma mais confiável de confirmar requisições do Googlebot. O processo envolve checar se o hostname DNS reverso corresponde ao padrão de domínio do Google e, em seguida, verificar se o lookup DNS direto desse hostname retorna o mesmo endereço IP. Esse método é especialmente valioso para sites de alto tráfego e redes de afiliados que precisam garantir atribuição de tráfego precisa e evitar que atividades fraudulentas de bots sejam contabilizadas como tráfego legítimo de motores de busca.
A análise de padrões de requisição fornece informações valiosas sobre o comportamento dos crawlers ao examinar como as requisições são distribuídas ao longo do tempo e entre os recursos do seu site. Crawlers legítimos de motores de busca seguem padrões previsíveis que diferem significativamente do comportamento de navegação humana ou de bots maliciosos. Eles costumam fazer requisições em intervalos consistentes, seguem um padrão lógico de navegação pela estrutura de URLs do seu site e respeitam as diretivas especificadas no seu arquivo robots.txt. Ao monitorar esses padrões, é possível identificar crawlers legítimos e diferenciá-los de atividades suspeitas.
Ao analisar os padrões de requisição, observe algumas características principais que indicam comportamento legítimo de crawler. Primeiro, examine a frequência e a distribuição das requisições—crawlers legítimos normalmente espaçam suas requisições para evitar sobrecarregar o servidor, muitas vezes seguindo algoritmos de recuo exponencial que diminuem o ritmo se receberem erros HTTP 500 ou outros indicadores de estresse do servidor. Segundo, analise o padrão de navegação por URLs—crawlers legítimos seguem links de maneira sistemática e respeitam a estrutura do site, enquanto bots maliciosos frequentemente fazem requisições aleatórias ou sequenciais para URLs que não existem ou não estão linkados no seu site. Terceiro, monitore os tipos de recursos requisitados—crawlers legítimos geralmente solicitam páginas HTML, arquivos CSS e JavaScript necessários para renderizar as páginas, evitando requisições desnecessárias a arquivos binários ou diretórios sensíveis.
Você pode implementar o monitoramento de padrões de requisição analisando os logs do servidor e identificando agrupamentos de requisições que compartilham características em comum. Ferramentas como plataformas de web analytics e softwares de análise de logs de servidor podem automatizar esse processo, sinalizando padrões incomuns. Por exemplo, se um único endereço IP faz 1.000 requisições por minuto para páginas de produtos diferentes em padrão sequencial, provavelmente é um crawler. Em contraste, crawlers legítimos de motores de busca normalmente fazem requisições com frequência bem menor, espaçando os acessos por vários segundos para respeitar os recursos do servidor e evitar mecanismos de limitação de taxa.
Seja o primeiro a saber sobre novos recursos e atualizações do produto.
A análise comportamental examina como crawlers interagem com o conteúdo e a tecnologia do seu site, fornecendo insights que ajudam a distinguir crawlers legítimos de outros tipos de bots. Uma das características comportamentais mais importantes é a capacidade de executar JavaScript. Motores de busca modernos como o Google renderizam páginas utilizando navegadores headless (sem interface gráfica), semelhantes ao Chrome, para executar JavaScript e acessar conteúdos gerados dinamicamente. Isso significa que crawlers legítimos vão executar códigos JavaScript nas suas páginas, enquanto muitos bots maliciosos ou scrapers simples não conseguem ou não executam JavaScript.
Você pode detectar a execução de JavaScript inserindo códigos de rastreamento que só são ativados quando o JavaScript está habilitado e funcional. Se uma requisição acessa sua página mas não dispara o rastreamento dependente de JavaScript, ou não carrega conteúdo gerado dinamicamente, isso indica que o solicitante pode não ser um crawler moderno de motor de busca. Além disso, crawlers legítimos normalmente carregam todos os recursos necessários para renderizar completamente a página, incluindo imagens, folhas de estilo e arquivos JavaScript, enquanto bots simples podem solicitar apenas o arquivo HTML, sem carregar os recursos de apoio.
Outro indicador comportamental importante é como os crawlers lidam com elementos interativos e envio de formulários. Crawlers legítimos de motores de busca não enviam formulários, não clicam em botões e não interagem com conteúdos dinâmicos de formas que poderiam causar efeitos colaterais indesejados como realizar pedidos ou modificar dados. Eles focam em ler e analisar o conteúdo, e não em interagir com ele. Bots maliciosos, por outro lado, frequentemente tentam interagir com formulários, enviar dados ou acionar ações que podem prejudicar seu site ou roubar informações. Ao monitorar esses padrões comportamentais, você pode identificar requisições que tentam interações não autorizadas e diferenciá-las das atividades legítimas de crawlers.
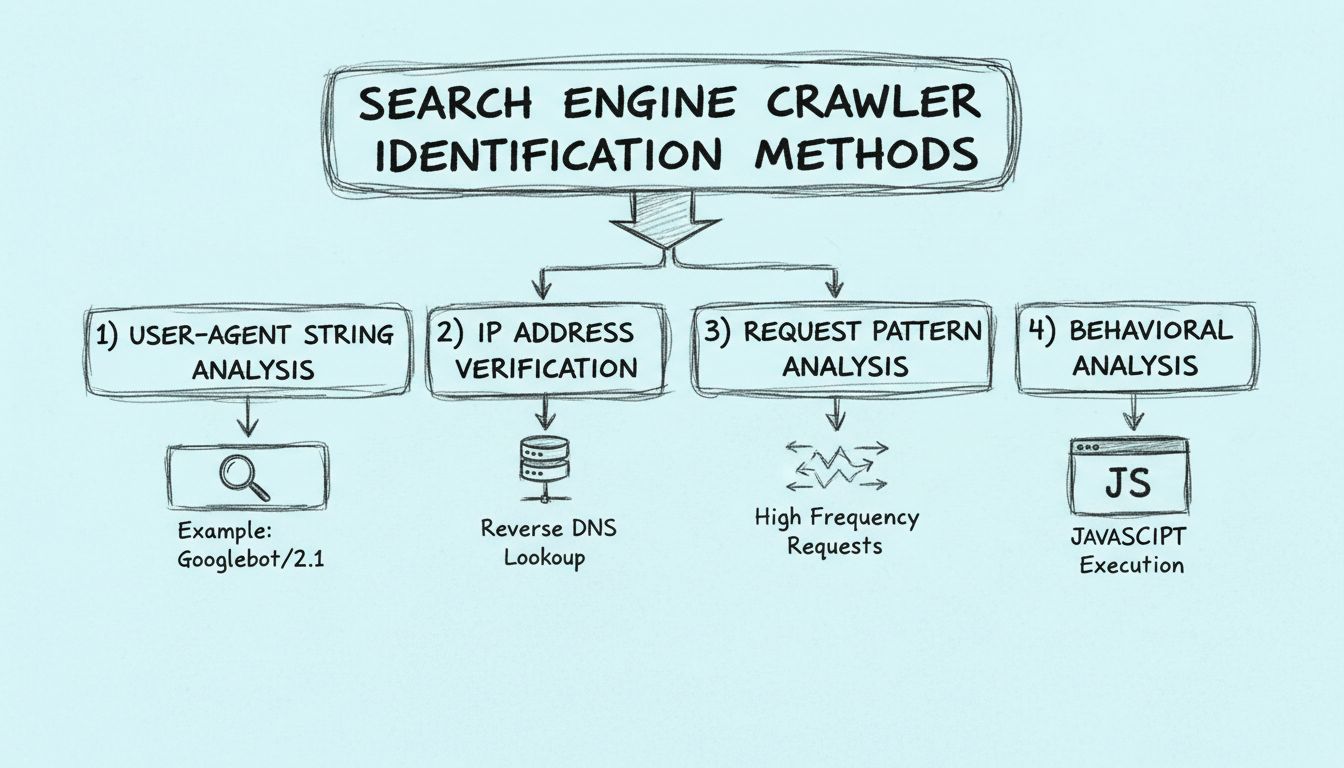
A abordagem mais eficaz para identificação de crawlers combina os quatro métodos em um fluxo de verificação abrangente. Em vez de confiar em um único método, a implementação de um sistema de verificação em camadas oferece proteção robusta contra crawlers falsificados e garante atribuição correta de tráfego. Comece capturando a string User-Agent e o endereço IP de cada requisição e, então, cruze esses dados com bancos de dados de crawlers conhecidos mantidos por motores de busca e organizações de segurança. Em seguida, realize um lookup DNS reverso para verificar se o hostname do endereço IP corresponde ao domínio do motor de busca alegado. Por fim, analise o padrão de requisição e as características comportamentais para garantir que a atividade esteja alinhada ao comportamento legítimo de crawlers.
Essa abordagem em múltiplas camadas é especialmente importante para redes de afiliados e plataformas de marketing de performance como o PostAffiliatePro, onde a atribuição correta de tráfego impacta diretamente nos cálculos de comissão e na integridade do programa. Ao implementar uma identificação abrangente de crawlers, você garante que seus sistemas de rastreamento de afiliados distinguem corretamente entre tráfego legítimo de motores de busca, tráfego de publicidade paga e tráfego orgânico de usuários. Essa precisão permite melhor análise de performance, cálculos de ROI mais exatos e maior capacidade de detecção de fraude.
A infraestrutura web moderna exige sistemas sofisticados de identificação de crawlers capazes de lidar com a complexidade do tráfego atual. Primeiro, mantenha uma lista atualizada de endereços IP e strings User-Agent de crawlers legítimos, assinando notificações oficiais dos principais motores de busca. Google, Bing e outros motores de busca publicam atualizações sempre que adicionam novos crawlers ou mudam sua infraestrutura, e manter-se informado sobre essas mudanças garante que seus sistemas de identificação estejam sempre atualizados. Segundo, implemente logs no servidor que capturem todos os metadados relevantes das requisições, incluindo strings User-Agent, endereços IP, horários e recursos acessados. Esses dados formam a base para análise de padrões e monitoramento comportamental.
Terceiro, considere implementar uma API ou serviço de verificação de crawlers que valide automaticamente a identidade em tempo real. Muitas plataformas de segurança e análise agora oferecem serviços de identificação de crawlers que mantêm bancos de dados atualizados de crawlers legítimos e conseguem verificar requisições em relação a esses bancos. Quarto, estabeleça políticas claras para lidar com atividades de crawlers não identificados ou suspeitos. Você pode optar por servir essas requisições normalmente enquanto as registra para análise posterior, ou implementar limitação de taxa para evitar exaustão de recursos. Por fim, revise e atualize regularmente suas regras e limites de identificação de crawlers com base nos padrões de tráfego observados e nas novas ameaças que surgirem. O cenário de rastreamento na web continua em evolução, e seus sistemas de identificação devem se adaptar para manter a eficácia.
Identificar crawlers de motores de busca requer compreensão abrangente de múltiplos métodos de verificação e a capacidade de combiná-los em um sistema de detecção eficaz. Ao analisar strings User-Agent, verificar endereços IP por meio de lookups DNS reversos, monitorar padrões de requisição e examinar características comportamentais, é possível distinguir de forma confiável crawlers legítimos de outros tipos de bots e fontes de tráfego. Essa capacidade é essencial para webmasters, desenvolvedores e afiliados que precisam entender suas fontes de tráfego e garantir o rastreamento preciso de performance. Os recursos avançados de análise e monitoramento de tráfego do PostAffiliatePro ajudam você a implementar esses métodos de identificação de forma eficaz, garantindo que seu programa de afiliados capture dados precisos e mantenha a integridade do programa em um cenário digital cada vez mais complexo.
O PostAffiliatePro é o principal software de gestão de afiliados que ajuda você a rastrear, gerenciar e otimizar sua rede de afiliados com precisão. Identifique fontes de tráfego legítimas e maximize a performance do seu programa de afiliados com análises avançadas e monitoramento em tempo real.
Crawlers acumulam dados e informações da internet visitando sites e lendo páginas. Descubra mais sobre eles.
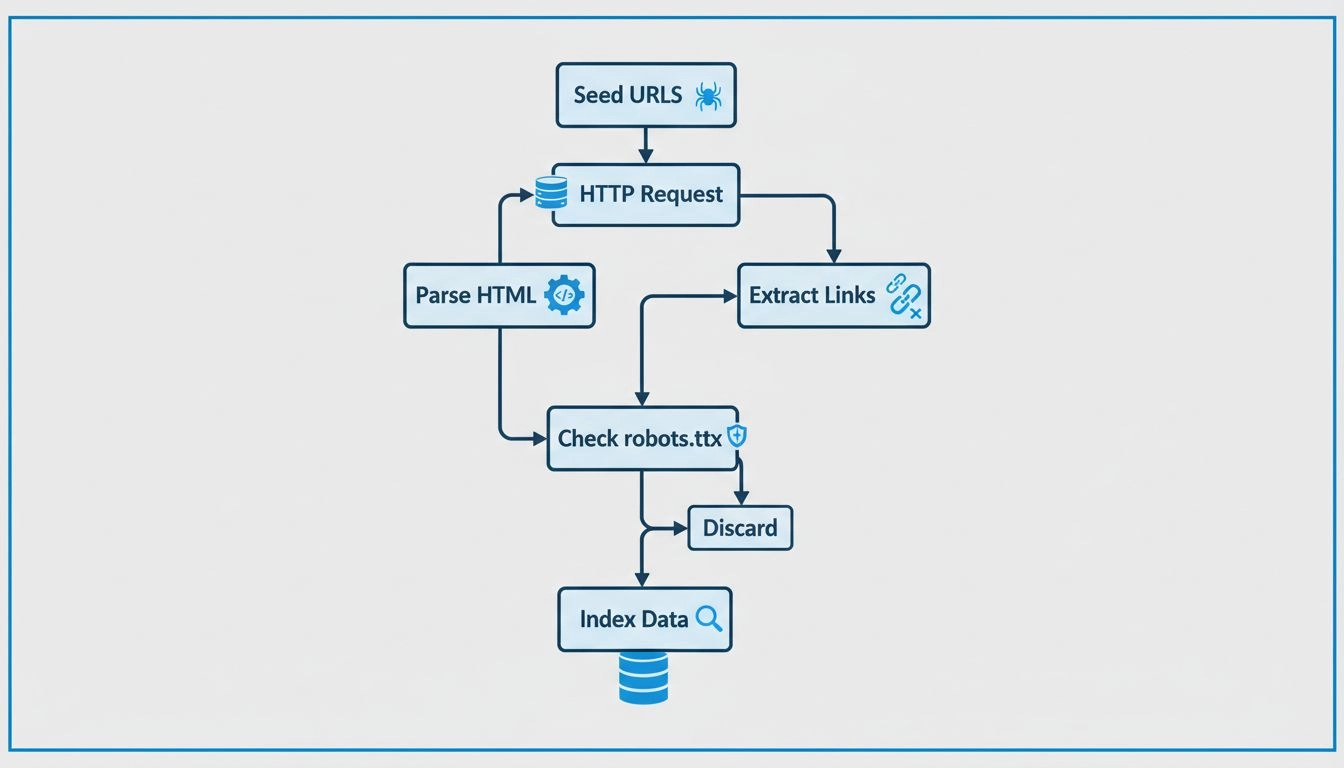
Descubra como funcionam os web crawlers, desde URLs iniciais até a indexação. Entenda o processo técnico, tipos de crawlers, regras do robots.txt e como eles im...
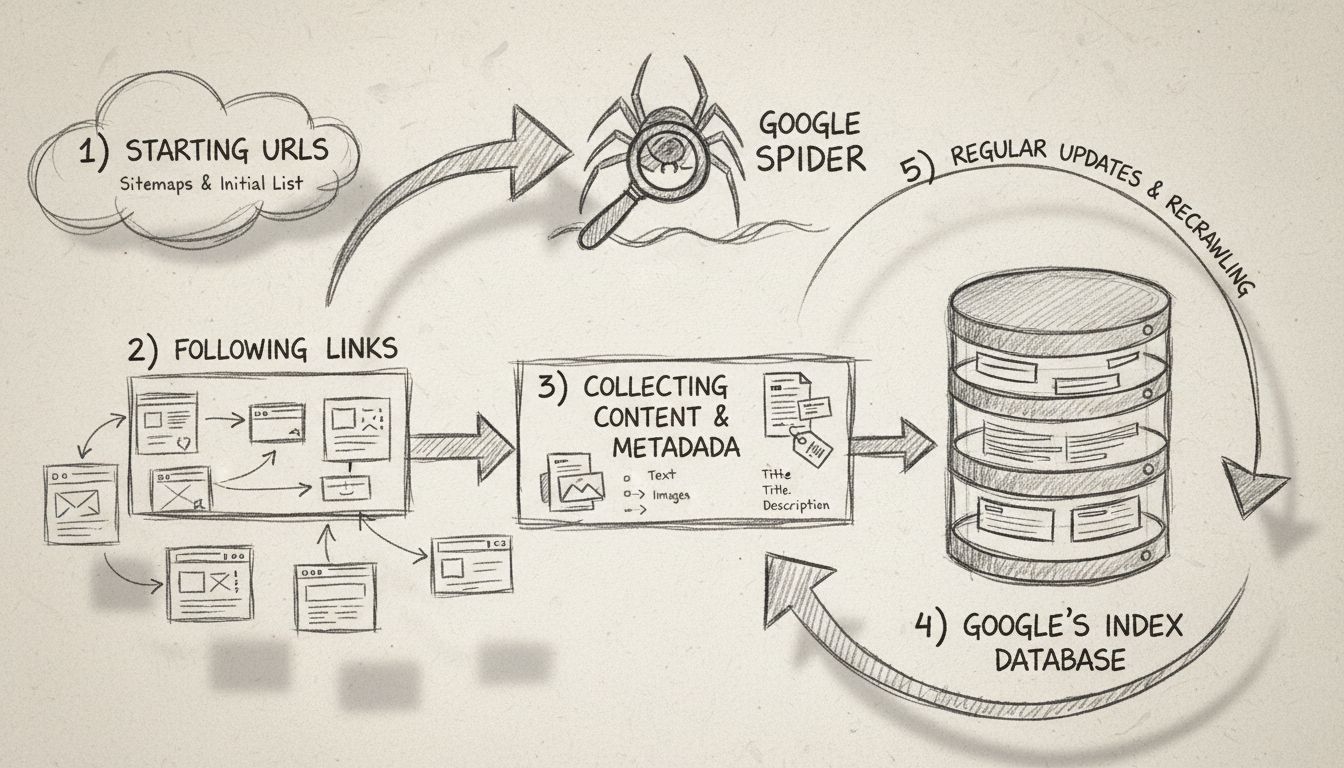
Descubra o que é o Google Spider (Googlebot), como ele rastreia e indexa sites e por que é essencial para o SEO. Aprenda como otimizar seu site para um melhor r...
Junte-se à nossa comunidade de clientes satisfeitos e forneça excelente suporte ao cliente com o Post Affiliate Pro.
See our privacy policy.