Por que os spiders da web são chamados de spiders de computador? Entendendo os rastreadores da web
Saiba por que os spiders da web são chamados de spiders de computador e como eles navegam pela internet. Descubra como funcionam os rastreadores dos motores de busca e sua importância para SEO e marketing de afiliados.
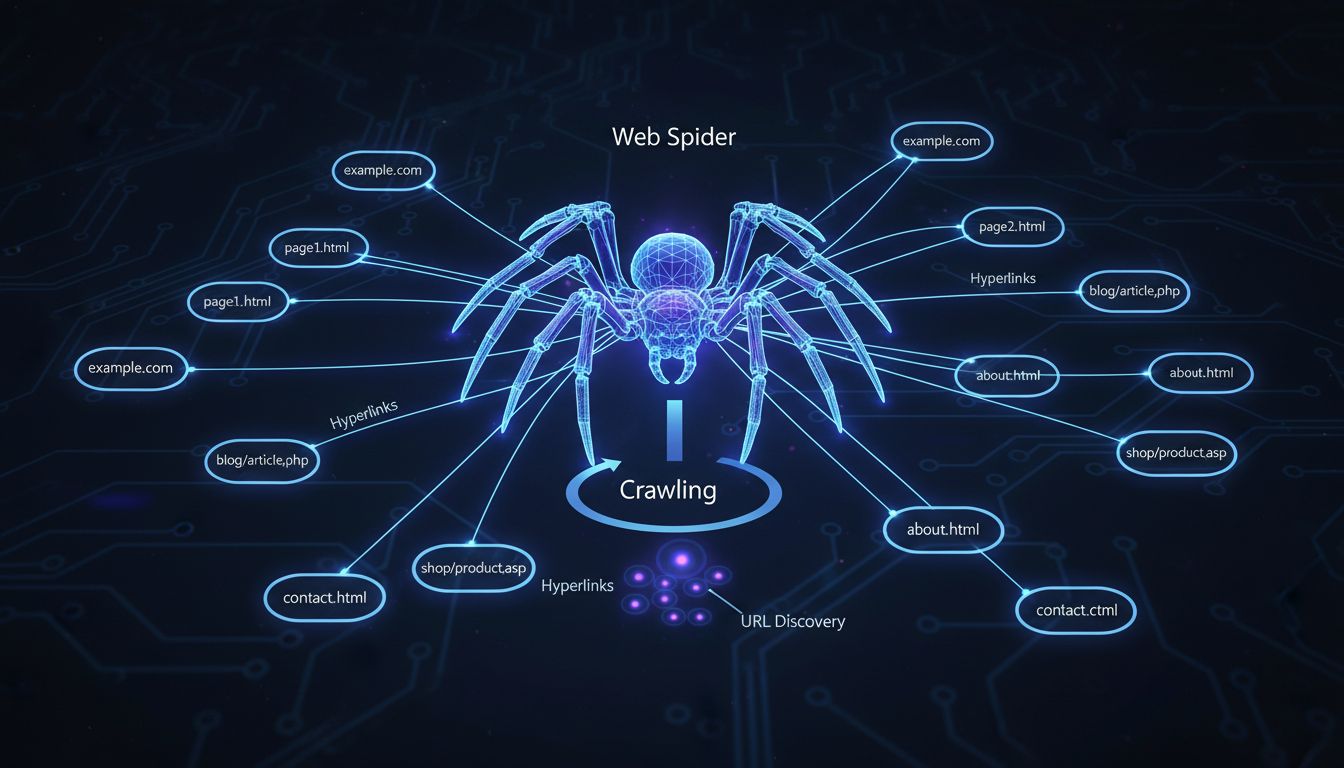
Por que eles são chamados de spiders de computador? Eles são chamados assim porque "rastreiam" a web.
Os spiders da web são chamados de spiders de computador porque eles "rastreiam" a internet seguindo hiperlinks de uma página para outra, assim como uma aranha se move em sua teia. Esses programas automatizados exploram sistematicamente sites para descobrir e indexar conteúdo para os motores de busca.
Entendendo a Metáfora da Aranha
O termo “spider de computador” origina-se de uma analogia inteligente que descreve perfeitamente como esses programas automatizados funcionam na internet. Assim como uma aranha real se move pela sua teia seguindo fios e conexões, um spider da web navega pela internet seguindo hiperlinks de uma página para outra. Essa metáfora se tornou tão intuitiva que hoje é a terminologia padrão usada por desenvolvedores web, profissionais de SEO e profissionais de marketing digital em todo o mundo. O nome captura a essência do comportamento do rastreador de forma facilmente compreensível tanto para públicos técnicos quanto não técnicos. Ao entender esse conceito fundamental, você começa a perceber como a infraestrutura da internet reflete de forma elegante sistemas naturais encontrados na natureza.
Como os Spiders da Web Rastreiam a Internet
Os spiders da web operam por meio de um processo sistemático e metódico que começa com uma lista inicial de URLs conhecidas. O rastreador começa visitando essas páginas iniciais e examinando cuidadosamente seu conteúdo e estrutura. Ao processar cada página, o spider identifica todos os hiperlinks presentes e os adiciona a uma fila de URLs para visitar em seguida. Esse processo se repete continuamente, permitindo que o spider avance cada vez mais fundo na web a cada iteração. O spider essencialmente cria um mapa da internet seguindo essas conexões, como um explorador traçando novos territórios ao seguir caminhos e trilhas. Essa abordagem sistemática garante que os motores de busca possam descobrir e catalogar milhões de novas páginas todos os dias.
Componente do Rastreador
Função
Propósito
Fila de URLs
Armazena lista de páginas a visitar
Organiza a sequência de rastreamento
Parser
Lê o conteúdo da página e o HTML
Extrai links e metadados
Indexador
Armazena informações da página
Cria banco de dados pesquisável
Agendador
Determina a frequência de rastreamento
Gerencia alocação de recursos
User-Agent
Identifica o rastreador
Comunica-se com servidores
O Processo Técnico por Trás do Rastreamento da Web
Antes que um spider da web inicie sua operação de rastreamento, os desenvolvedores devem estabelecer instruções claras e pré-definidas que guiem o comportamento do spider. Essas instruções determinam quais páginas rastrear, com que frequência revisitar páginas e quais informações extrair de cada página. O rastreador então executa essas instruções automaticamente, seguindo o algoritmo exatamente como programado. Quando o spider visita um site, ele primeiro verifica o arquivo robots.txt, que é um arquivo de texto que especifica regras para o acesso de rastreadores. Esse protocolo, conhecido como protocolo de exclusão de robôs, permite que os proprietários dos sites comuniquem suas preferências sobre quais áreas de seu site devem ser rastreadas e quais devem ser evitadas. As informações coletadas pelo rastreador dependem inteiramente das instruções fornecidas, tornando a fase de configuração crucial para alcançar os resultados desejados.
Diferentes Tipos de Spiders da Web
Os spiders da web existem em várias formas, cada um projetado para fins e aplicações específicas. Spiders de motores de busca como o Googlebot são os tipos mais conhecidos, usados pelos principais motores de busca para descobrir e indexar páginas para os resultados de pesquisa. Rastreador focado, por outro lado, limita seu escopo a tópicos ou áreas específicas da internet, criando índices detalhados de conteúdos de nicho. Spiders de análise web ajudam webmasters a monitorar seus próprios sites acompanhando métricas como visitas, links quebrados e desempenho de páginas. Spiders de comparação de preços coletam automaticamente informações de preços de vários fornecedores, permitindo que sites de comparação ofereçam aos usuários dados atualizados do mercado. Spiders de validação de e-mails verificam endereços de e-mail e checam problemas de entregabilidade. Cada tipo de spider serve a um propósito distinto no ecossistema digital, e entender essas diferenças ajuda os proprietários de sites a otimizarem seus sites para os rastreadores apropriados.
Por Que os Motores de Busca Dependem dos Spiders da Web
Os motores de busca não podem funcionar sem spiders da web porque esses programas automatizados são responsáveis por descobrir novos conteúdos e manter os índices de busca atualizados. Quando você faz uma consulta de pesquisa, o motor de busca não pesquisa a internet ao vivo em tempo real. Em vez disso, ele pesquisa em um índice criado por spiders que previamente visitaram e catalogaram bilhões de páginas. Sem os spiders, os motores de busca não teriam como saber que conteúdo existe na internet ou como organizá-lo para recuperação. A capacidade do spider de seguir hiperlinks significa que novas páginas podem ser descobertas automaticamente, sem necessidade de envio manual. Esse processo automatizado de descoberta é o que torna a internet pesquisável e acessível a bilhões de usuários em todo o mundo. A eficiência e velocidade dos spiders da web impactam diretamente a rapidez com que novos conteúdos aparecem nos resultados de busca.
A Importância dos Spiders da Web para SEO e Marketing Digital
Para proprietários de sites e profissionais de marketing digital, compreender os spiders da web é essencial porque esses rastreadores determinam se o seu conteúdo aparecerá nos resultados de busca. Se um spider de motor de busca não conseguir rastrear seu site, suas páginas não serão indexadas e não aparecerão nos resultados de busca, independentemente da qualidade do seu conteúdo. Por isso, profissionais de SEO focam muito em tornar os sites “amigáveis para rastreadores”, garantindo estrutura adequada, carregamento rápido e navegação clara. Afiliados, em especial, se beneficiam de entender o comportamento dos spiders, pois isso impacta diretamente como suas páginas de afiliados são descobertas e ranqueadas. O PostAffiliatePro reconhece que programas de afiliados bem-sucedidos dependem de visibilidade, e nossa plataforma ajuda você a otimizar sua rede de afiliados para garantir que os spiders dos motores de busca possam facilmente descobrir e indexar seu conteúdo de afiliado. Tornando suas páginas acessíveis aos rastreadores, você aumenta as chances de que potenciais afiliados e clientes encontrem seu programa via pesquisa orgânica.
Gerenciando e Controlando a Atividade dos Spiders da Web
Os proprietários de sites têm várias ferramentas à disposição para gerenciar como os spiders interagem com seus sites. O arquivo robots.txt é o principal mecanismo para comunicar preferências aos rastreadores, permitindo especificar quais páginas devem ser rastreadas e quais devem ser evitadas. A tag meta noindex oferece controle adicional ao impedir que páginas específicas sejam indexadas mesmo se forem rastreadas. Para páginas que devem ser rastreadas mas não indexadas, o atributo nofollow pode ser usado em links para evitar que os spiders sigam essas conexões específicas. Proprietários de sites também podem usar o Google Search Console e outras ferramentas de webmaster para monitorar a atividade dos rastreadores e identificar questões que possam impedir a indexação adequada. No entanto, é importante notar que, enquanto essas ferramentas ajudam a gerenciar spiders legítimos de motores de busca, bots e scrapers maliciosos podem ignorar essas diretivas. Por isso, muitos sites implementam medidas de segurança adicionais e sistemas de gerenciamento de bots para se proteger de atividades nocivas de rastreadores, enquanto ainda permitem que spiders benéficos acessem seu conteúdo.
A Diferença Entre Spiders e Scrapers
Embora spiders da web e scrapers da web ambos coletem dados automaticamente de sites, eles servem a propósitos muito diferentes e operam sob diretrizes éticas distintas. Spiders da web, especialmente os usados por motores de busca, seguem o protocolo robots.txt e respeitam as preferências do proprietário do site sobre o que deve ser rastreado. Scrapers, por outro lado, frequentemente ignoram essas diretrizes e copiam páginas inteiras de conteúdo para republicar em outros lugares, o que pode configurar violação de direitos autorais e roubo de propriedade intelectual. Spiders normalmente coletam e organizam metadados sobre páginas, enquanto scrapers copiam todo o conteúdo visível. Spiders de motores de busca são geralmente considerados benéficos pois ajudam os sites a obter visibilidade, enquanto scrapers costumam ser vistos como maliciosos, pois roubam conteúdo e podem prejudicar o desempenho do site. Compreender essa distinção é importante para proprietários de sites que precisam diferenciar tráfego legítimo de rastreadores de atividades nocivas de bots. O PostAffiliatePro ajuda gerentes de afiliados a monitorar e gerenciar o tráfego para suas páginas de afiliados, garantindo que spiders legítimos possam acessar seu conteúdo enquanto protegem contra atividades de scraping maliciosas.
Maximize a visibilidade da sua rede de afiliados
Assim como os spiders da web descobrem e indexam seu conteúdo, o PostAffiliatePro ajuda você a descobrir e gerenciar toda a sua rede de afiliados. Acompanhe cada interação de rastreador e otimize o desempenho do seu programa de afiliados com nossa plataforma líder do setor.
Por que os rastreadores da web são chamados de spiders? Entendendo a tecnologia de indexação web
Descubra por que os rastreadores da web são chamados de spiders, como funcionam e seu papel fundamental na indexação dos mecanismos de busca. Conheça os mecanis...
O que é um Vírus de Computador Spider? Definição, Ameaças & Guia de Proteção
Saiba o que são os vírus de computador spider, como eles se espalham pelas redes e descubra estratégias eficazes de proteção. Guia abrangente para entender amea...
8 min read
Você estará em boas mãos!
Junte-se à nossa comunidade de clientes satisfeitos e forneça excelente suporte ao cliente com o Post Affiliate Pro.